

引言
数值模式预报被认为是目前天气预报中最有效的预报手段,过去几十年中,得益于理论研究的不断深入、气象观测系统的发展、同化技术的进步以及大型计算机计算能力的突破,数值天气预报精度得到极大提升(Bauer et al., 2015;Bonavita et al., 2016),并凭借其客观化、定量化的优势在天气分析、精细化要素预报等方面发挥了不可替代的作用。但是由于大气的混沌特性及受制于不完善的物理框架和初始、边界条件,现阶段数值模式对降水、温度等地面要素的预报与实况还存在不同程度的偏差(孙敏等,2018;佟华等,2006;符娇兰和代刊,2016),而且不同模式对不同地区、不同季节和不同天气过程的预报稳定性也不一样,因而需要在数值预报的基础上进一步释用以提高预报产品的精度。目前针对模式温度偏差的后验订正主要包括模式输出统计法及卡尔曼滤波法等统计释用方法,并通过调整最优时窗、空间插值优化及多模式集成等方案(何珊珊等,2021;王丹等,2015;吴启树等,2016;薛谌彬等,2019),明显改善了模式的系统性偏差问题,有效提高了2 m温度的预报准确率,使得误差在空间分布上更为均匀。近年来,随着计算机技术和应用数学的发展,机器学习逐渐在众多任务中取得超越传统方法的效果,其中LightGBM(Light Gradient Boosting Machine)算法是数据挖掘、分类预测等领域的研究热点,广泛应用于各行各业的分类及回归问题中。在气象领域,前人尝试将LightGBM算法应用于定时气温预报订正、强对流天气分类识别、大气能见度预报订正模型及包含多种机器学习算法的融合模型预测最大风速等工作中(刘新伟等,2021;刘军中,2021;谭江红等,2018;王志宇,2019),其中湖北省气象台建立的LightGBM定时气温预报订正模型已经实现业务化,其准确率在客观产品中排名靠前。
四川整体地势西高东低,地形地貌复杂,气候复杂多样,不同地域的气温预报受下垫面影响较大,且不同季节、不同天气过程等因素也造成了气温预报的不确定性。对四川地区模式预报的2 m温度检验表明,不同的主客观预报产品的预报能力呈现出明显的季节性及区域性差异,且在平稳天气时预报性能较优,而在天气变化的转折过程中预报稳定性及准确率波动较大。目前已有的LightGBM温度订正业务模型主要针对定时的2 m温度进行订正,而对转折性天气过程的温度变化订正研究较少。为此,本文首先分区域、分季节对四川省的气温转折性天气过程进行统计和特征分析,在此基础上基于LightGBM算法建立气温转折过程温度变化订正模型并检验其性能,以期为实际业务中转折性天气过程的2 m温度变化预报提供参考。
1 资料
(1)四川省156个国家气象站逐日最高、最低2 m温度观测数据,资料时段为1990年1月1日至2019年12月31日,共计30 a,用于统计逐日变温分布并定义气温转折过程;(2)上述观测资料及对应时段的NCEP/NCAR逐日再分析资料(水平分辨率为1.0°×1.0°),用于气温转折过程LightGBM模型建模;(3)2020年1月1日至12月31的日最高2 m温度观测数据及对应时段的ECMWF(European Centre for Medium-Range Weather Forecasting)细网格模式(分辨率为0.125°×0.125°)资料,用于模型检验。其中再分析资料和模式资料选取的要素场包括1 000~500 hPa温度场、1 000~100 hPa相对湿度场、925~500 hPa风场、500 hPa位势高度场、海平面气压场、白天时段(09:00—20:00)降水量,并将这些要素通过双线性插值法插值到观测站点。文中所有时间均为北京时;另外,文中附图涉及地图均基于国家测绘地理信息局标准地图服务网站下载的审图号为GS(2016)1552号的标准地图制作,底图无修改。
2 气温转折过程定义及其特征
2.1 气温转折过程定义
曹萍萍等(2018)根据海拔高度差异将四川地区划分为盆地、高原与盆地的边坡过渡区、川西南山地及川西高原4个区域(图1)。其中,盆地以海拔高度低于500 m的丘陵地区为主;高原与盆地的边坡过渡区主要为海拔高度500~1 000 m的龙门山沿线地区,受地形影响大;川西南山地主要为攀西地区,以海拔1 500~3 000 m的山地为主;川西高原主要为甘孜和阿坝两州,以海拔3 000 m以上的高原为主。本文采用此划分方法统计4个区域的逐日最高温度及最低温度变化绝对值分布,结果如图2所示。可以看出,四川省4个区域的最高温度日变温幅度均比最低温度大,且绝对值分布更为分散。不论是最高温度还是最低温度,川西高原的日变温幅度均最大,川西南山地次之,盆地最小。从最高温度极值分布来看,川西高原和川西南山地均超过20.0 ℃,且差异较小,盆地为18.7 ℃,明显低于其余3个区域;盆地、高原与盆地的边坡过渡区、川西南山地及川西高原的最低温度极值分别为13.9、14.4、15.3和16.6 ℃。虽然极值较大,但各区域最高温度和最低温度的第90个百分位数均低于各自极值的1/3,说明绝大多数的日变温绝对值位于低值段,其中最高温度的日变温中位数为1.8~2.0 ℃,最低温度的日变温中位数为1.1~1.6 ℃。另外,4个区域的最高温度和最低温度均值均略高于中位数。
图1
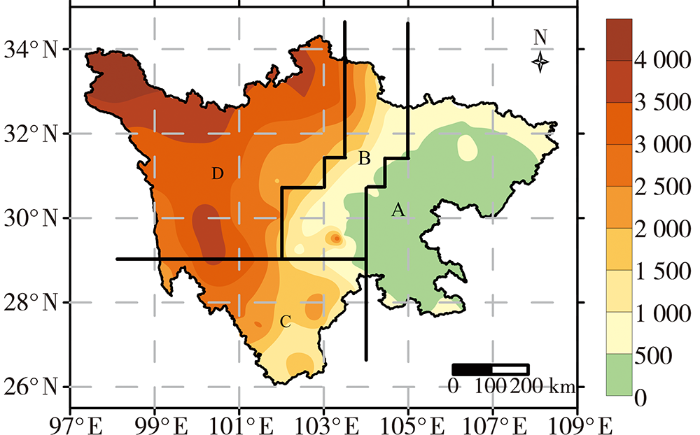
图1
基于海拔(填色,单位:m)的四川地区分区
(A区域:盆地;B区域:高原与盆地的边坡过渡区;C区域:川西南山地;D区域:川西高原)
Fig.1
Partitioning of Sichuan region based on altitude (the color shaded, Unit: m)
(A: the basin, B: the slope transition zone of plateau and basin,C: the mountains of southwestern Sichuan, D: the plateau in western Sichuan)
图2
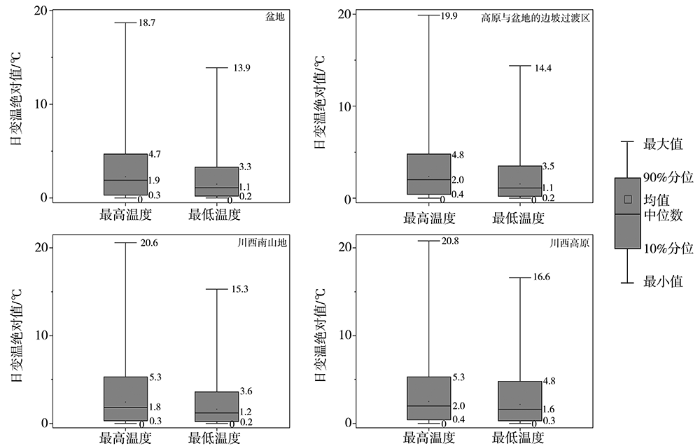
图2
1990—2019年四川4个区域最高、最低2 m温度日变温绝对值的箱线图
Fig.2
The box plots of absolute values of daily variation of the maximum and minimum 2 m temperature in four regions of Sichuan Province from 1990 to 2019
肖红茹等(2020)统计1980—2017年四川盆地的寒潮气温变化特征显示,72 h平均气温累积降温的第90个百分位数为5.4 ℃,与四川盆地寒潮天气业务标准(72 h内日平均气温持续下降超过6.0 ℃)较为吻合。由于最高温度较最低温度变化更明显,且在寒潮天气过程中24 h内主要表现为最高温度的下降,最低温度普遍下降不明显且近50%的站点趋于上升,因此选用最高温度逐日变温的第90个百分位数作为气温转折过程的统计标准,由于4个区域数值差异不超过0.6 ℃,且考虑统计方便,故将四川省气温转折过程的日变温标准统一设置为5.0 ℃。定义某一天某个区域大于等于50%的测站最高温度较前一天出现一致的升温或降温,且幅度大于等于5.0 ℃时,则该区域出现一次气温转折过程。
2.2 气温转折过程分布特征
图3为1990—2019年四川省4个区域的气温转折过程分布。全省近30 a共出现1 433次气温转折过程,其中升温过程略多于降温过程。
图3
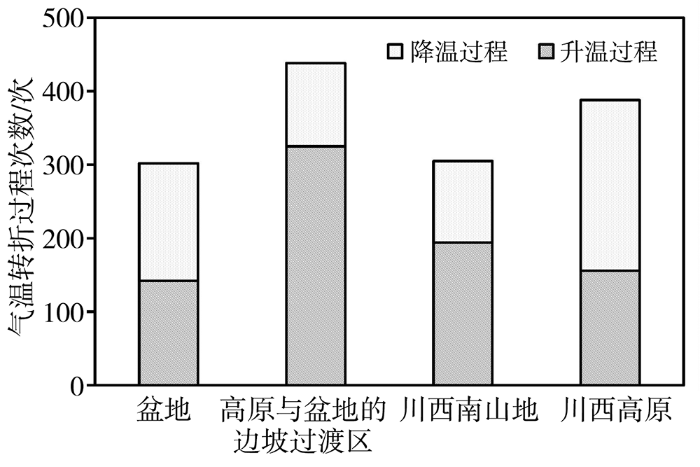
图3
1990—2019年四川4个区域升温及降温转折过程分布
Fig.3
Distribution of temperature transitional processes in four regions of Sichuan Province during 1990-2019
出现气温转折过程最多的区域是高原与盆地的边坡过渡区(438次),其次是川西高原(388次),最少的是盆地(302次),川西南山地出现气温转折过程的次数虽然与盆地相比差异不明显,但其升温过程明显较多,两者升温过程占比分别为63.6%和47.0%。对于气温转折过程较多的高原与盆地边坡过渡区和川西高原,升温与降温过程也表现为不同的分布特征,其中前者升温过程占比最高(74.2%),而后者升温过程占比最低(40.2%)。
进一步分季节对四川省各个区域的气温转折过程进行统计(图4)后发现,各区域的气温转折过程分布具有明显的季节差异,均是春季最多、冬季最少,且春季的过程次数明显多于其余3季。但不同区域夏、秋季又展现出不同的变化特征,盆地、高原与盆地的边坡过渡区及川西高原3个区域均是夏季的气温转折过程略多于秋季,而川西南山地则是秋季多于夏季。另外值得注意的是,盆地气温转折过程最少,其春、秋、冬季也均是4个区域中最少,但其夏季的过程次数却仅次于高原与盆地的边坡过渡区,位列第二。
图4
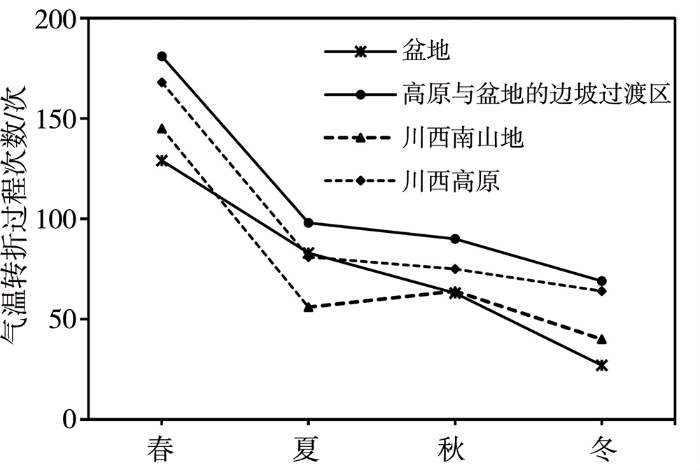
图4
1990—2019年四川4个区域气温转折过程的季节分布
Fig.4
Seasonal distribution of temperature transitional processes in four regions of Sichuan Province during 1990-2019
3 基于LightGBM算法的气温转折过程温度变化订正模型
3.1 算法简介
LightGBM是一种轻量级的梯度提升学习框架,由微软公司2016年开源,它以GBDT(Gradient Boosting Decision Tree)模型为基础,将许多准确率较低的树模型组合起来,采用梯度提升迭代算法,在每次迭代时通过向损失函数的负梯度方向移动使得损失函数越来越小,最终得到一棵较优的树,并以此作为预测模型,其实质是一种将弱学习器提升为强学习器的集成学习算法(曹渝昆和朱萌,2019;张丹峰,2018)。此外,LightGBM采用2种创新的采样算法,分别是互斥特征捆绑EFB(Exclusive Feature Bundling)和基于梯度的单边采样GOSS(Gradient-based One-side Sampling):EFB算法针对维数特别大的特征,将互斥的特征捆绑在一起并加入一个偏移常量形成一个新的特征,从而减少特征数目,因此降低了数据特征规模,提高了模型训练速度;GOSS算法排除了大部分具有小梯度的样本,只使用剩余样本进行信息增益估计,在保证信息增益的同时减小训练量,提高模型的泛化能力。因此,LightGBM与其他传统GBDT框架相比,具有训练效率高、内存消耗小、准确率高及对并行学习和大数据友好等优点。
GBDT中的决策树是一种预测模型,其流程是自根节点至叶子节点的递归过程,在每个中间节点寻找一个属性划分,采用CART(Classification and Regression Trees)二叉回归树作为基学习器,内部结点特征的取值为“是”和“否”,递归地二分每个特征,从而将输入特征空间划分为有限个单元,并在这些单元上确定预测的概率分布。
本文中的“树”模型即是基于温、压、湿、风等特征因子的取值,通过构建树型决策结构来对最高温度逐日变化进行分析。设数据集为M,构建回归树的大体思路如下:①考虑数据集M上的所有特征因子j,遍历每一个特征下所有可能的取值或者切分点s,来寻求最优切分并将数据集M划分成两部分M1和M2,其衡量方法是误差平方和最小化;②分别计算M1和M2的误差平方和,选择最小的误差平方和对应的特征与分割点,生成2个子节点(将数据划分为两部分);③对上述2个子节点递归调用步骤①、②,直到满足停止条件(如叶子个数上限)。回归树构建完成后,将整个输入空间划分为多个子区域,每个子区域的输出为该区域内所有训练样本的最高温度逐日变化平均值。模型中采用的是均方误差(Mean Squared Error, MSE)损失函数,其数学表达为:
3.2 特征因子选取
特征因子向量描述了机器学习模型的内在构成因子,对特征因子的选取及其数据质量决定了模型效果的上限,一方面需要选取与待预测量相关性最强的影响因子从而学习到数据之间的内在客观规律,另一方面需要避免选取的因子过多而引起无效学习或陷入过拟合,即对气温转折过程中最高温度逐日变化的订正在训练集中效果很好,但在实际的测试集中效果很差。根据天气学原理,局地温度的变化主要取决于温度平流和非绝热因子,在实际业务中,重点关注大气中低层的温度平流,而对于非绝热因子中的太阳辐射项,由于没有直接预报产品,主要关注相对湿度、低云量、总云量(与大气整层相对湿度有关)等要素。因而本项目选取的特征如下:925~500 hPa的风场及其变化场(风场矢量场分解为u、v分量,共20个因子),代表影响某地的天气系统;1 000~100 hPa的相对湿度场及其变化场(20个因子),代表某地上空的天空状况;1 000~500 hPa的温度场及其变化场(12个因子),代表大气的基本冷暖状态及冷暖平流;此外选取海平面气压场及其24 h变压(2个因子),用于衡量冷空气活动及其强度;选取500 hPa位势高度变化场,用于衡量大气中层气压场的波动;选取白天时段(09:00—20:00)的降水量,用于衡量降水对气温变化的影响。
图5为不同区域特征因子与最高温度变化之间的相关系数绝对值达0.3以上,且通过α = 0.05的显著性检验的因子分布,选取这些因子进行建模,其中盆地有30个因子,高原与盆地边坡过渡区有26个因子,川西南山地有30个因子,川西高原有28个因子。
图5
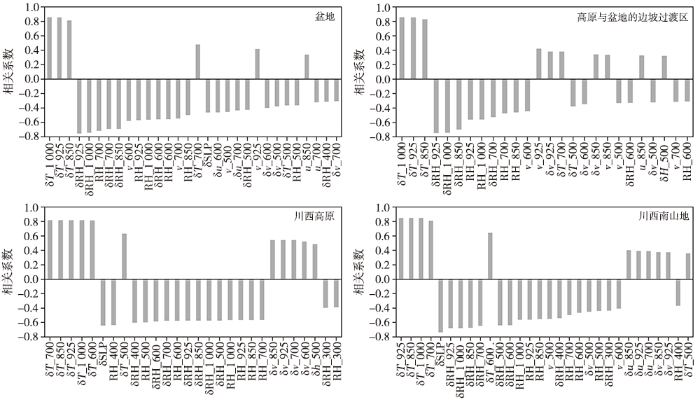
图5
四川不同区域与最高温度变化相关系数绝对值达0.3以上的特征因子分布
(横坐标轴δH表示位势高度变化场,δT表示温度变化场,RH和δRH分别表示湿度场及其变化场,u、v和δu、δv分别表示u、v风场及其变化场,短划线后面的数字表示所在的位势高度层次,δSLP表示海平面24 h变压)
Fig.5
The distribution of characteristic factors with the absolute value of correlation coefficients over 0.3 between maximum temperature change and characteristic factors in different regions of Sichuan Province
(The horizontal axis δH represents the potential height variation field, δT represents the temperature variation field, RH and δRH represent the humidity field and its variation field, respectively, u, v and δu, δv represent the wind fields and their variation fields, respectively, the numbers after the short line represent the geopotential height, δSLP represents the sea level pressure variation in 24 hours)
整体上来看,各区域与最高温度变化正相关最高的因子为大气中低层温度的变化,负相关最高的因子为大气中低层的相对湿度变化及相对湿度值。此外,对于川西南山地和川西高原,与最高温度变化负相关最为明显的因子是海平面24 h变压,相关系数分别达-0.73和-0.64,这与四川地区预报员在制作高原地区预报时特别关注海平面气压场的变化这一经验相一致;南北风分量及其变化对最高温度的影响明显大于东西风分量,这是由于南风气流和北风气流的热力性质不一样;白天时段的降水与4个区域最高温度日变化均为负相关,但绝对值较小,可能是因为降水并非都发生在最高温度出现时段。
3.3 检验指标
选取预报准确率(R)及平均绝对误差(Mean Absolute Error, MAE)来评估对温度变化的预报及订正性能。计算公式(肖明静等,2012)如下:
(1)预报准确率
式中:R是对温度变化的预报绝对偏差不大于2.0 ℃的百分率,Nr为预报变温与实况变温之差不超过±2.0 ℃的站(次)数,Nf为预报的总站(次)数。
(2)平均绝对误差
式中:Fi代表预报的温度变化值, Oi代表实况观测的温度变化值,N为总站(次)数。平均绝对误差反映的是预报变温与实况变温的平均偏离程度。
3.4 模型训练
经过特征过程处理后的数据进入LightGBM模型,通过网格搜索方式训练调参和交叉验证方式优化算法。其中特征过程处理主要是将数据中的空值使用特征列的平均值进行填充,模型调整的主要参数包括迭代次数(n-estimators)、学习率(learning-rate)和叶节点的数目(num-leaves),目标是使得训练集对温度逐日变化的订正准确率较高,但过拟合问题不严重,在交叉验证中,模型训练样本和交叉验证样本比例为7.5∶2.5。待LightGBM模型达到最优后,进行模型检验评估。最终使用的模型参数见表1。
表1 模型主要参数
Tab.1
| n-estimators | learning-rate | num-leaves | boosting-type |
|---|---|---|---|
| 100 | 0.10 | 192 | GBDT |
表2为各区域验证集的准确率及平均绝对误差,可以看出:盆地、高原与盆地的边坡过渡区模型准确率明显高于川西南山地和川西高原,其中盆地的准确率最高(86.59%),平均绝对误差最小(1.07 ℃);川西南山地的准确率最低(64.31%),平均绝对误差最大(1.87 ℃);全省平均准确率为78.64%,平均绝对误差为1.35 ℃。
表2 LightGBM模型在四川不同区域验证集中的准确率及平均绝对误差
Tab.2
| 盆地 | 高原与盆地的边坡过渡区 | 川西南山地 | 川西高原 | 全省 | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| R/% | MAE/℃ | R/% | MAE/℃ | R/% | MAE/℃ | R/% | MAE/℃ | R/% | MAE/℃ | ||||
| 86.59 | 1.07 | 83.03 | 1.19 | 64.31 | 1.87 | 65.14 | 1.83 | 78.64 | 1.35 | ||||
4 LightGBM模型2 m温度变化订正效果检验
将训练的LightGBM模型用于2020年气温转折过程最高温度日变温的订正,其中盆地、高原与盆地边坡过渡区、川西南山地及川西高原出现的气温转折过程次数分别为10、17、15和12次。特征因子为ECMWF细网格模式的24 h及48 h时效的相关预报量,并将订正结果与ECMWF细网格模式预报、中央台城镇预报指导报(SCMOC)及四川省气象台数值预报客观释用城镇预报指导报(SPCO)进行对比(表3),结果显示:(1)在气温转折过程中,对于最高温度变化,LightGBM模型在川西南山地区域的准确率较ECMWF模式预报的准确率低2.15%,对应的平均绝对误差高0.2 ℃,这可能是由于一方面该地区纬度较盆地偏南,一般处于降温过程的后期,模式预报相对稳定与准确,另一方面四川地区业务应用中的其他2 m温度订正方法均显示,川西南山地的东北部是年平均误差最大的地区之一,本身订正难度较大。而在其余3个区域,LightGBM模型的准确率均较ECMWF模式有所提高,其在盆地、高原与盆地边坡过渡区及川西高原准确率提高的幅度分别为2.30%、7.67%及15.60%,高原与盆地边坡过渡区的平均绝对误差减小0.31 ℃,川西高原的平均绝对误差减小0.68 ℃,整体来看,LightGBM模型在上述2个区域的订正效果较好。(2)与中央台城镇预报指导报(SCMOC)对比,LightGBM订正模型在各区域的准确率均高于前者,平均绝对误差均小于前者,其中盆地、高原与盆地边坡过渡区、川西南山地及川西高原的准确率较SCMOC预报分别提高18.02%、17.94%、5.72%及4.80%,平均绝对误差分别减小1.04、1.09、0.46及0.55 ℃。(3)与四川省气象台数值预报客观释用城镇预报指导报(SPCO)对比,LightGBM订正模型在盆地、高原与盆地边坡过渡区、川西高原的准确率较SPCO预报分别提高10.60%、8.14%及8.40%,平均绝对误差分别减小0.05、0.20及0.20 ℃,而在川西南山地,LightGBM订正模型的准确率较SPCO低4.78%,平均绝对误差大0.25 ℃。(4)从全省平均来看,LightGBM订正模型的准确率最高(53.60%),平均绝对误差最小(2.19 ℃),效果最好,但其在川西南山地的订正效果不及ECMWF模式及SPCO的预报。
表3 LightGBM模型、ECMWF模式、SCMOC及SPCO在测试集中的准确率及平均绝对误差对比
Tab.3
| 区域 | LightGBM | ECMWF | SCMOC | SPCO | ||||
|---|---|---|---|---|---|---|---|---|
| R/% | MAE/℃ | R/% | MAE/℃ | R/% | MAE/℃ | R/% | MAE/℃ | |
| 盆地 | 50.18 | 2.90 | 47.88 | 2.51 | 32.16 | 3.94 | 39.58 | 2.95 |
| 高原与盆地的边坡过渡区 | 58.44 | 2.13 | 50.77 | 2.44 | 40.50 | 3.22 | 50.30 | 2.33 |
| 川西南山地 | 45.58 | 2.79 | 47.73 | 2.59 | 39.86 | 3.25 | 50.36 | 2.54 |
| 川西高原 | 57.60 | 2.13 | 42.00 | 2.81 | 52.80 | 2.68 | 49.20 | 2.33 |
| 全省 | 53.60 | 2.19 | 48.32 | 2.53 | 39.58 | 3.36 | 47.26 | 2.54 |
此外,值得注意的是,该模型在验证集上的平均准确率为78.64%,而在测试集上的平均准确率为53.60%,可能的原因是验证集中使用的特征因子为再分析资料,而测试集中使用的因子为ECMWF模式预报数据,模式预报的要素本身存在一定误差,而该模型并未考虑模式预报误差。
为了更直观地分析LightGBM模型的改善效果,图6绘制了LightGBM模型与ECMWF模式、SCMOC及SPCO指导报在测试集中准确率的差值分布。可以看出,相对于ECMWF模式,LightGBM模型对89个测站的准确率有所提高,区域主要集中在盆地中部、南部以及川西高原大部;相对于SCMOC,LightGBM模型在113个测站的准确率有所提高,区域覆盖四川省大部;相对于SPCO,LightGBM模型在92个测站的准确率有所提高,区域主要集中在盆地及川西高原大部。
图6
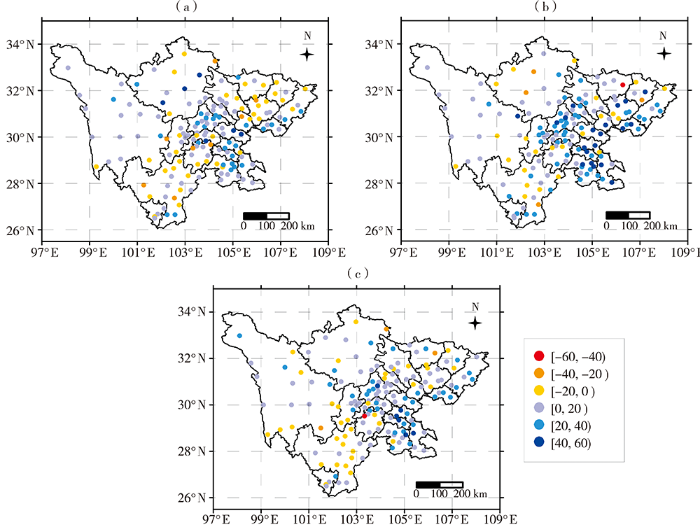
图6
LightGBM模型与ECMWF(a)、SCMOC(b)及SPCO(c)在测试集中准确率的差值分布(单位:%)
Fig.6
The difference distribution of accuracy between the LightGBM model and ECMWF (a),SCMOC (b) and SPCO (c) in the test set (Unit: %)
5 结论
本文在对四川地区1990—2019年不同区域气温转折过程进行统计分析的基础上,基于LightGBM订正算法,选取与每个区域气温转折过程最高温度变化相关系数绝对值达0.3及以上的指标作为因子进行建模,并检验该模型在2020年气温转折过程中的2 m温度变化订正性能。得到以下主要结论:
(1)从区域看,出现气温转折过程最多的是高原与盆地边坡过渡区,最少是盆地;从升温及降温过程分布看,盆地升温与降温过程约各占一半,高原与盆地边坡过渡区及川西南山地升温过程多于降温过程,川西高原降温过程多于升温过程。
(2)各区域气温转折过程具有明显的季节差异,均表现为春季最多、冬季最少,且春季气温转折过程明显多于其余3季。
(3)在1990—2019年验证集中,LightGBM模型在盆地、高原与盆地边坡过渡区的准确率明显高于川西南山地和川西高原;四川地区平均准确率为78.64%,平均绝对误差为1.35 ℃。
(4)在2020年气温转折过程的测试集中,LightGBM订正模型的准确率为53.60%,平均绝对误差为2.19 ℃。与ECMWF原始模式、中央台指导预报(SCMOC)及四川省气象台客观释用指导报(SPCO)对比表明,LightGBM订正模型整体效果优于另外3家预报,且高原与盆地边坡过渡区及川西高原准确率的提高尤为明显。
本文基于LightGBM算法建立的模型可以为实际业务转折性天气过程的2 m温度变化预报提供一定参考,并且在逐日2 m温度的预报订正中进行推广应用。在后续研究中,需要考虑模式本身误差进行建模,以期进一步提高模型的效率和精度。
参考文献
基于LightGBM算法的强对流天气分类识别研究
[J].
强对流天气将导致多种灾害性天气, 但由于其突发性强且尺度较小, 在气象业务工作中仍难以准确地预警和预报。本文基于LightGBM (Light Gradient Boosting Machine)算法, 利用甘肃三个地区的C波段雷达回波产品以及地面观测数据, 构建了LightGBM模型, 并分类判识了三类主要的强对流天气[冰雹、 雷暴大风、 短时强降水(短强)]。结果表明, 在2011 -2017年训练集中, LightGBM模型表现较好, 整体误判率仅为4.9%。在2018年的独立样本测试中, 模型对三类强对流和非强对流天气的整体误判率为7.0%, 对三类强对流天气的平均命中率(Probability of Detection, POD)为86.4%, 平均临界成功指数(Critical Success Index, CSI)为64.3%, 平均空报比率(False Alarm Ratio, FAR)为29.0%。其中, 短强的误判率最低, POD和CSI最高, FAR也最小, 而雷暴大风和冰雹的误判率和评分比较接近。因此, 本文构建的LightGBM模型对强对流天气的分类识别较为理想, 首次对三类主要的强对流天气实现了自动化预警, 在未来的气象业务自动化工作中有广阔的应用前景。
一种逐时气温预报方法
[J].利用2006~2010年陕西10地市逐小时的气温和逐日的最高气温、最低气温、平均总云量、降水量资料,通过线性回归方法建立了一种基于日最高气温和最低气温预报以及临近气温实况资料的逐时气温预报模型,并对2011年每天的逐时气温预报进行检验。结果表明:该方法在晴天多云和阴雨天的预报能力依次减弱,其中晴天和多云天02~18时的预报效果好于19时至次日01时的,而阴雨天01~10时的预报效果好于其它预报时段的;当日最高气温和最低气温预报较为准确时,西安站各预报时刻的准确率均在60%以上,其中14~17时的准确率较高,晴天的达到100%,多云天的在96%~99%之间,阴雨天的准确率偏低一些,特别是11~17时较晴天和多云天偏低了12%~27%;该方法可以将24h日最高(低)气温预报细化到逐时气温预报,同时考虑了气温日变化的地域差异季节特征、以及在晴天、多云和阴雨天的不同表现,具有一定的业务应用和推广价值。
气温预报方法研究及其应用进展综述
[J].气温预报一直是天气预报的重要组成部分,本文对气温预报方法进行综述,分析其优缺点,并提出新的气温精细化预报方法的可行性思路,为提高气温预报质量提供参考。
The quiet revolution of numerical weather prediction
[J].
The evolution of the ECMWF hybrid data assimilation system
[J].


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}