

引言
降水是公众最关心的天气现象之一,强降水可造成城市内涝、农田渍涝,甚至引发泥石流、山洪等地质灾害,给当地造成重大经济损失和人员伤亡[1⇓-3]。因此,提升降水预报准确率尤为关键,这需依赖数值模式预报能力的提高和模式产品的合理释用[4],而降水预报检验是提高模式预报性能认知、合理释用模式产品的重要环节[5-6]。几十年来,气象学者开展了大量模式降水预报检验分析工作。20世纪60年代,设计出双变量的预报检验列联表[7],可通过列联表将事件进行分类,然后计算诸如命中率(probability of detection,POD)、误警率(false alarm ratio,FAR)等技巧评分。随后发展了TS(threat score)评分[8]、临界成功指数(critical success index,CSI)[9]、ETS(equitable threat score)[10]以及一系列针对空间检验的评分指数,如S1评分[11]、ACC(anomalous correlation coefficient)[12]、FQI(forecast quality index)[13]、FSS(fractions skill score)评分[14]等。随着集合预报的广泛应用,与其相关的各类评分日益增多,包括Brier评分[15]、排列概率评分[16]、Wilson概率评分[17]等。由此可见,目前针对降水预报产品的检验指标非常丰富。伴随着数值模式的不断发展,确定性模式产品和集合预报产品的种类不断增多,基于模式结果订正的多种降水客观预报方法[18]得到应用。因此,在实际业务中往往同时面对多种预报产品、同一预报产品有多种检验评估指标,如何对多产品多指标进行综合分析?更全面地认识不同预报产品性能,目前仍缺乏有效手段。
聚类分析是一种研究多维空间点与点之间关系的方法[19],在数据挖掘、评估等领域得到有效应用[20⇓-22]。层次聚类方法是一种重要的聚类方法,包括"自顶向下"的分裂层次聚类和"自底向上"的凝聚层次聚类(agglomerative hierarchical clustering,AHC)。面对气象数据要素繁多、时间序列长、观测站点众多的特征,由于层次聚类方法能够充分挖掘海量数据信息,有效减少分析成本、客观全面刻画数据整体特征[23],广泛应用于风场、降水[24-25]等要素的分析。随着降水预报产品及其检验指标的日益增多,AHC在无任何预先定义的类别数分类方面有显著优势[26]。为了更好地探查预报误差的综合特征,本研究拟将AHC这一显著优势应用于降水预报检验中,以期为预报及模式改进提供有益参考。
1 资料和方法
1.1 资料及预处理
本文主要针对2019年全国智能预报技术方法交流大赛降水网格预报产品,基于凝聚层次聚类方法进行评分,预报产品包括全国范围的国家气象中心指导预报(SCMOC)和中国气象科学研究院的无缝隙分析预报前沿系统预报产品(简记S1)及31个省(市、区)客观预报(简记S2~S32),共33组客观预报产品,预报时间为6—9月,空间分辨率5 km,时间分辨率为3 h和24 h,且均为每日20:00(北京时,下同)起报。为比较分析,还使用了美国国家环境预测中心(National Centers for Environmental Prediction,NCEP)和欧洲中期天气预报中心(European Centre for Medium-Range Weather Forecasts,ECMWF)的全球数值预报产品,空间分辨率分别为0.5°×0.5°和0.125°×0.125°,并处理成与客观预报产品相同的分辨率。因此,共有35个降水预报产品形成检验样本集。另外,降水预报检验选用了中国10 459个国家气象观测站降水资料,并采用邻近点进行空间插值。
1.2 检验方法
按照此次大赛检验方案,降水预报产品采用晴雨预报准确率(percentage correct,PC)和平均相对误差(mean relative error,MRE)指标进行检验。计算公式如下:
式中:NA为有降水且预报正确的站(次)数;NB、NC分别为空报和漏报的站(次)数;ND为无降水且预报正确的站(次)数;Ro、Rf(mm)分别为观测、预报降水量。当实况和预报值都为0时,MRE计为0。
针对强降水预报采用TS评分、偏差幅度B和Bias评分3个检验指标,其中Bias评分仅用于分析空报、漏报情况(聚类中未涉及)。计算公式如下:
上述指标中,PC和TS评分均为正指标(即数值越大表示预报效果越好),而偏差幅度B和MRE均为逆指标(即数值越小表示预报效果越好)。为便于后续更清楚地呈现聚类结果,针对逆指标进行正向化处理,即对数值取反。
考虑不同地区降水存在明显差异,故根据国家气象中心规定的不同地区、不同累积时长下强降水的阈值(表1)进行相应检验。
表1 强降雨阈值
Tab.1
| 省(市、区) | 3 h内 | 24 h内 |
|---|---|---|
| 西藏、新疆、青海、宁夏 | 10 | 25 |
| 其他省份 | 20 | 50 |
综上,针对35个降水预报产品,检验评估指标包括:①3 h晴雨预报准确率(PC03_X)、②3 h强降水预报TS评分(TS03_X)、③3 h强降水预报偏差幅度(B03_X)、④3 h降水量预报平均相对误差(MRE03_X)、⑤24 h晴雨预报准确率(PC24)、⑥24 h强降水预报TS评分(TS24)、⑦24 h强降水预报偏差幅度(B24),其中,X为1~8,表示8个时次。可见,每个样本共计35项检验指标。因此,对35个预报产品样本分别进行35项指标检验,综合分析得到各预报产品的预报性能特征。
1.3 层次聚类方法
1.3.1 层次聚类方法概述
图1
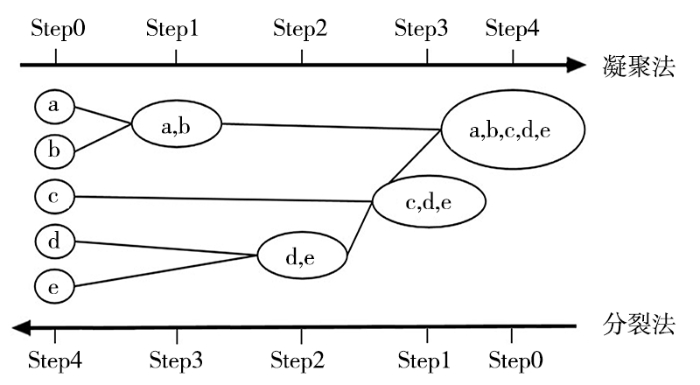
1.3.2 凝聚层次聚类算法过程
(1)特征矩阵
降水预报产品的评分结果可用特征矩阵表示,矩阵的行表示降水预报产品,列表示预报产品检验指标。因此,将35个待分类的样本Xi看作论域X中的元素,即
式中:xij为第i个样本的第j个检验指标。
由于各检验评分具有不同的量纲(量级),在聚类前需进行标准化处理,公式如下:
式中:
(2) 基于Ward法聚类
为衡量各预报产品样本间的相似性,首先采用欧式距离建立距离矩阵,欧式距离的计算公式如下:
式中:dmn为样本Xm和Xn间的欧氏距离,m、n∈{1,2, …,35};j为检验指标。
图2
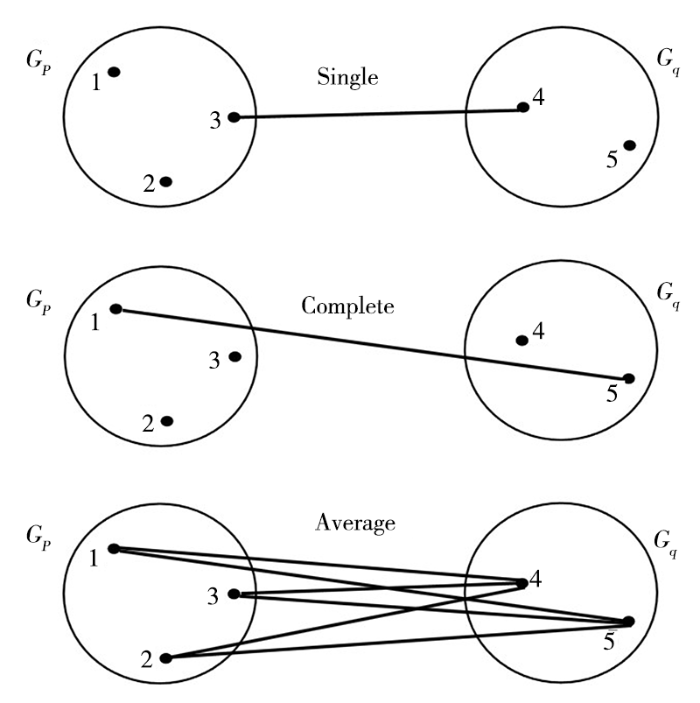
图2
层次聚类的3种相似度度量方法示意图
Fig.2
Schematic diagram of three similarity measurement methods for hierarchical clustering
2 聚类结果与分析
2.1 总体聚类结果
图3是35个预报样本的35项检验指标的聚类结果(暖色调表示预报效果较为理想,冷色调表示预报效果不理想)。为方便理解,按照从大类到小类的顺序标注,下标数字的顺序表示层次,数字表示在该层的第几类,如
图3
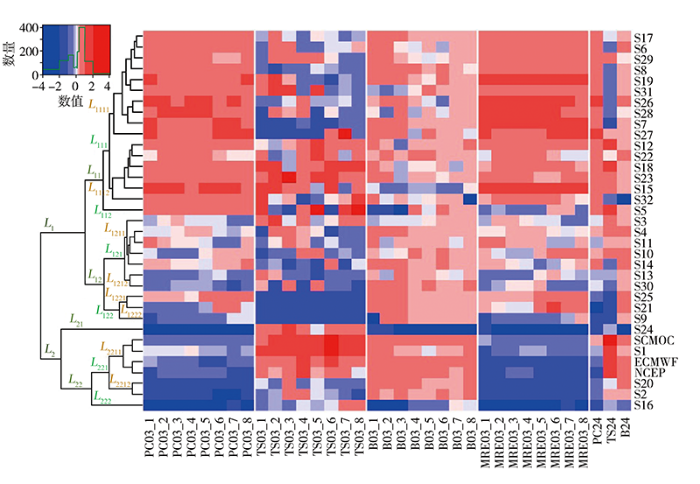
图3
基于Ward度量方法的网格预报层次聚类结构及热图
Fig.3
Hierarchical clustering structure and heat map for grid forecast samples based on Ward similarity method
(1)总体上,35个预报样本分为较明显的4类:PC03、PC24和强降水B03、B24及MRE03预报效果较为理想,但强降水TS03和TS24评分表现相对较差的
(2)所有预报样本,差异较明显的是PC03 和MRE03检验指标。
(3)各样本强降水TS03评分和B03表现无明显的一致性,其中SCMOC和S1对于强降水TS03评分有良好的订正能力。
(4)检验指标中,PC03和强降水TS03评分随预报时效变化不明显,而强降水B03则存在前3 h表现较好而后变差的特征。
2.2 客观预报与ECMWF预报对比
上述35个样本中,ECMWF和NCEP是模式预报产品,其他样本为客观预报产品(模式产品释用)。聚类分析发现,ECMWF和NCEP模式预报产品划为同一子类,其共同特征表现为强降水TS03评分较高、B03相对较小,其他检验指标相对较差;相对于模式预报样本,客观预报样本的改进主要体现在PC03、PC24和MRE03方面。可见,对于全球预报模式来说,多数客观订正方法主要改进了弱降水的预报精度(晴雨预报)。另外,SCMOC和S1为全国范围预报,聚类分析也将这2类预报划分为同一子类;相对于模式预报,SCMOC、S1客观预报的绝大多数检验指标都有所改进,改进效果较明显的是强降水TS03评分。由于ECMWF、NCEP、SCMOC、S1这4个产品预报范围为全国,其评分结果被划为同一子类(
为了与ECMWF全球数值预报产品比较,选取逐3 h检验指标,统计其余34个预报样本中比ECMWF预报性能好的样本个数(表2)。为明确样本TS评分的提升是否由增加空报所致,除PC、TS、B、MRE这4项检验指标外,增加了Bias评分(若Bias
表2 34个样本逐3 h预报结果优于ECMWF的个数
Tab.2
| 检验指标 | 23:00 | 02:00 | 05:00 | 08:00 | 11:00 | 14:00 | 17:00 | 20:00 |
|---|---|---|---|---|---|---|---|---|
| PC | 24 | 23 | 24 | 25 | 30 | 31 | 28 | 26 |
| MRE | 28 | 30 | 30 | 31 | 32 | 31 | 31 | 29 |
| TS | 6 | 13 | 12 | 2 | 7 | 5 | 9 | 8 |
| B | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| Bias | 15 | 14 | 16 | 17 | 11 | 17 | 22 | 21 |
图4
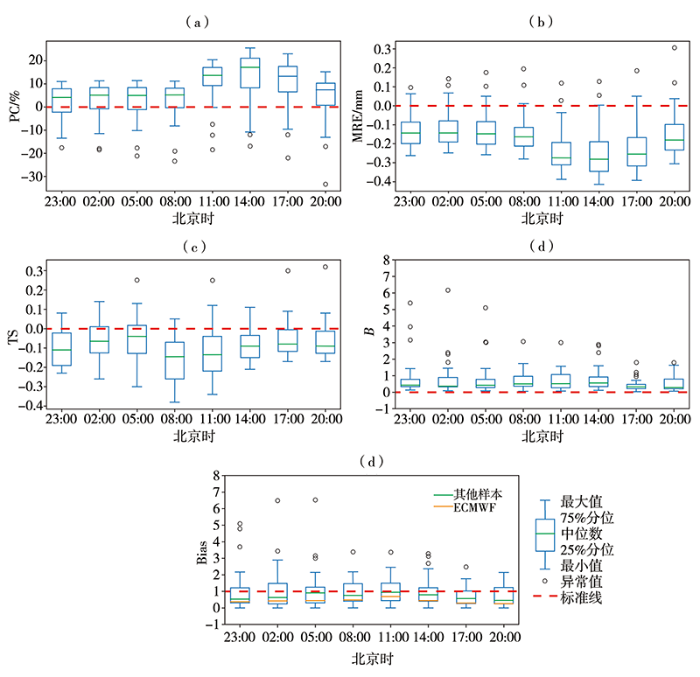
图4
34个样本相对于ECMWF的3 h晴雨预报准确率(a)、平均相对误差(b)、TS评分(c)及偏差幅度(d)差值和Bias评分(e)
Fig.4
The difference of 3-hour rain probability percentage correct (a), MRE (b), TS score (c) and bias amplitude (d) between 34 forecast samples and ECMWF product and Bias score (e)
2.3 检验指标的区域特征
聚类后发现,35个样本存在一定的区域特征。从表3看出,晴雨预报和降水量相对误差预报较好的
表3 L1111和L1112包含的省(市、区)
Tab.3
| L1111 | L1112 | ||||||
|---|---|---|---|---|---|---|---|
| 华北 | 东北 | 华中 | 华东 | 西北 | 华东 | 华中 | |
| 内蒙古 天津 河北 山西 | 辽宁 | 湖北 | 山东 | 陕西 宁夏 新疆 | 浙江 江苏 安徽 江西 福建 | 河南 | |
为进一步验证该结果,将31个省(市、区)客观订正预报(S2~S32)和全国范围预报(SCMOC、ECMWF、NCEP、S1)的检验指标分区域统计。从图5看出,35个样本的PC03绝大部分在60%~90%之间,华北和华东地区所有时次的PC03均高于全国和其他区域,最低为华南地区,这与聚类结果表现一致;全国范围的强降水TS03评分整体高于区域,且B03在各时刻都相对较低,而华南区域的B03高于其他区域,这与聚类结果相对应;除华南地区外,其他区域各预报时刻降水量的MRE03均较全国偏小,区域及全国的MRE03整体随时间呈缓慢上升趋势,尤其在08:00(距离起报12 h)后上升趋势更明显,这可能与模式预报时效有关,即预报时效越长,预报结果会相应变差。
图5
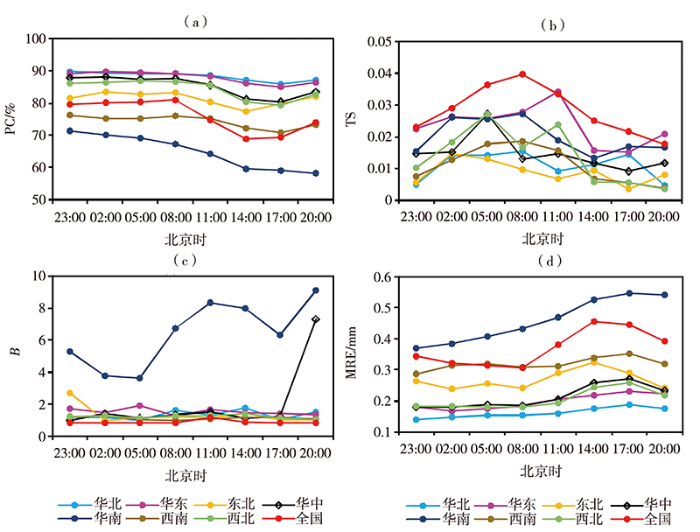
图5
不同区域预报样本3 h检验指标随时间变化
(a)PC,(b)TS,(c)B,(d)MRE
Fig.5
The change of 3-hour verification indexes for forecast samples with time in different regions
(a) PC, (b) TS, (c) B, (d) MRE
图6
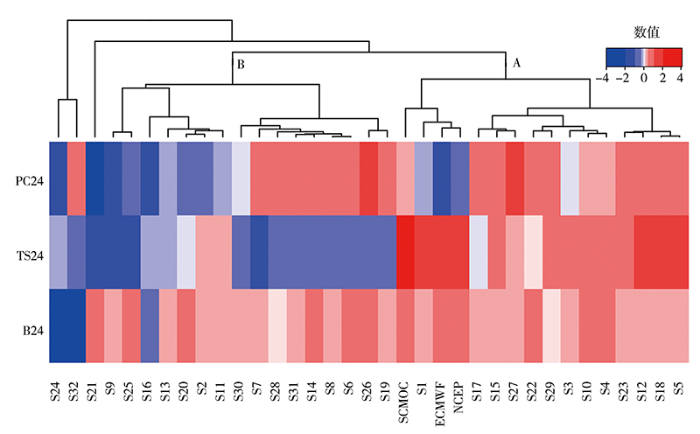
图6
24 h检验指标的层次聚类结构及热图
Fig.6
Hierarchical clustering structure and heat map for 24 h test indexes
3 检验指标对聚类结果的影响
为探究检验指标对聚类结果的影响,单独将35个样本24 h检验指标(PC24、TS24、B24)进行凝聚层次聚类分析(图6)。可以看出,S32和S24因偏差幅度远大于其他样本被聚为一类,而S21因晴雨预报准确率远低于其他样本被单独划分为一类,剩余的32个样本聚为A和B两大类,二者的显著差异为A类中样本的PC24和TS24检验指标评分明显高于B类,尤其是A类中ECMWF、NCEP和S1的TS24评分表现明显好于B类样本。A类中ECMWF、NCEP、S1、SCMOC全国范围的样本聚为一个子类,这与图3聚类结果相似,且SCMOC的TS评分最高,而S5、S18、S12和S23的聚类结果与评估指标减少前的也非常相似,24 h检验指标呈现出TS评分和PC均较高的特征。B类中,样本S20、S13、S16、S25、S9对于24 h晴雨预报把握不足(PC24均表现为冷色调),而S19、S26、S6、S8、S14、S31、S28、S7、S30的强降水TS24评分表现相对较差。
综上所述,通过对格点预报产品从整体(35项评估指标)和部分(24 h的3项评估指标)2个角度进行凝聚层次聚类,发现全国范围的ECMWF、NCEP、S1、SCMOC样本均聚为一类。减少评估指标,聚类结果发生较大改变的是24 h评估指标中在四大类划分上影响程度较小且本身又具有明显特征的样本,如S32。这说明针对不同评估指标进行凝聚层次聚类,其结果存在一定的差异性,只有部分样本的聚类结果不变,总体上呈现大差异里蕴含小相似的特征,检验指标需根据关注的问题进行选择。
4 不同相似度度量方法聚类差异性对比
为比较不同相似度度量方法聚类产生的差异,统计Single、Complete、Average和Ward方法聚类结果的相关系数(表4),并进行α=0.05的显著性检验,发现4种方法聚类结果均两两显著相关,其中Complete和Average与Ward方法聚类结果的相关性较高,相关系数为0.60左右,而Single与Ward方法聚类结果的相关性相对较弱,相关系数为0.44。另外,Single和Average方法的聚类结果具有极显著的正相关,相关系数高达0.96。
表4 不同相似度度量方法聚类结果的相关系数
Tab.4
| 方法 | Single | Complete | Average | Ward |
|---|---|---|---|---|
| Single | 1 | 0.76 | 0.96 | 0.44 |
| Complete | 1 | 0.79 | 0.60 | |
| Average | 1 | 0.59 | ||
| Ward | 1 |
图7是Ward方法聚类结果及与其相关性最小的Single、最大的Complete方法聚类效果对比。可以看出,3种方法对样本S24、S16和S8、S29、S17、S6的聚类结果完全一致。针对其他样本,Single与Ward的聚类结果差异较大,前者是将2个不同类中距离最近的2个样本之间的距离作为类间距离(类间距离越大,类别特征越清晰;反之,类间距离越小,类别特征越模糊),直接将该距离最短的划分为一类,故对于降水检验指标较为敏感,其聚类结果在底层的类中聚为相同子类的情形较少,类间距离较小,无法明显看出类间特征;Complete与Ward的聚类结果较为相似,仅个别样本类别有变化,其中全国范围的ECMWF、NCEP、SCMOC、S1样本仍聚为一个子类,类与类间的特征比Single表现得更明显。因此,聚类效果的类别特征从清晰到模糊的相似度度量方法依次为Ward、Complete、Average(图略)、Single。
图7
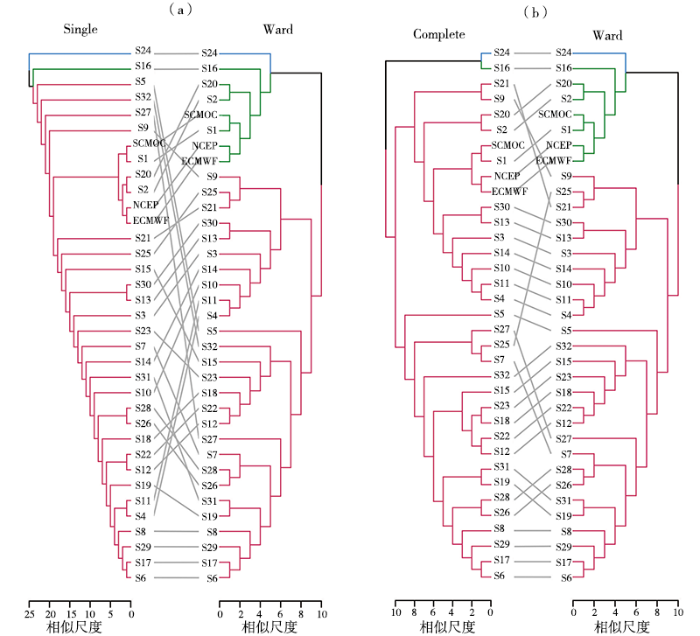
图7
Single(a)和Complete(b)与Ward方法的聚类效果对比
Fig.7
Comparison of clustering effect between Single (a), Complete (b) and Ward methods
5 结论与讨论
本文以2019年6—9月全国智能预报技术方法交流大赛的网格预报数据及国家气象中心指导预报、欧洲中期天气预报中心和美国国家环境预测中心的全球模式预报数据为样本集,采用凝聚层次聚类方法,对多预报样本的多检验指标进行综合分析,较全面地认识各样本的预报性能及异同。具体结论如下:
(1)凝聚层次聚类方法能够清晰地将35个预报样本在不同层级上分为不同的类,处于同一类的样本的预报性能具有较高的相似性,而不同类之间的预报性能有明显差异,有利于综合分析各预报样本的性能。
(2)聚类结果显示,35个预报样本可分为较明显的4类,各类间主要区别是PC03和MRE03检验指标,其中两类在PC03和MRE03上的预报性能明显高于另外两类,而强降水的TS03评分和B03在4类间差异不明显。总体上,这4类由PC03、MRE03、TS03、B03指标决定,表明针对晴雨和强降水预报可能需要采用不同的客观订正方法。
(3)不同行政区域的降水评分呈现不同的特征,华北和华东地区所有时次的PC03均高于其他区域,其中华南地区最低。绝大部分客观预报(模式产品释用)在逐3 h晴雨和降水量相对误差的预报性能上优于ECMWF模式预报,但在强降水预报中客观预报的性能不及ECMWF,主要表现为漏报,说明对于强降水预报的释用还存在较大困难。
降水预报性能的检验方法较多,面对不同时效、种类的降水预报产品,往往同时存在大量的检验评估结果。凝聚层次聚类方法能够比较全面、系统地综合分析各预报结果性能。在聚类分析过程中,采用不同的评估指标,聚类结果往往存在明显差异,但具有高相似度的预报产品仍然被划分到一个子类,这一方面反映聚类方法具有一定的稳定性,另一方面说明需要合理选择检验指标使得分类结果更具有针对性。另外,聚类过程中不同类间相似度度量方法的差异主要表现为类别特征的清晰程度。本文降水预报检验聚类的4种类间相似度度量方法从清晰到模糊依次为Ward、Complete、Average、Single法。
参考文献
Intercomparison of spatial forecast verification methods: identifying skillful spatial scales using the fractions skill score
[J].
The skill of ECMWF medium-range forecasts during the year of tropical convection 2008
[J].
Statistical theory and methodology in science and engineering
[M].
Statistical methods in the atmospheric sciences
[M].
The critical success index as an indicator of warning skill
[J].
Applying a general analytic method for assessing bias sensitivity to bias-adjusted threat and equitable threat scores
[J].
Verification of prognostic charts
[J].
Cumulative results of extended forecast experiments I. model performance for winter cases
[J].
A new metric for comparing precipitation patterns with an application to ensemble forecasts
[J].
Scale-selective verification of rainfall accumulations from high-resolution forecasts of convective events
[J].
Verification of forecasts expressed in terms of probability
[J].
A scoring system for probability forecasts of ranked categories
[J].
A strategy for verification of weather element forecasts from an ensemble prediction system
[J].
A method for cluster analysis
[J].
On the application of hierarchical cluster analysis for synthesizing low‐level wind fields obtained with a mesoscale boundary layer model
[J].
A tool for hierarchical climate regionalization
[J].
Implementing agglomerative hierarchic clustering algorithms for use in document retrieval
[J].
Hierarchical grouping to optimize an objective function
[J].
Application of multivariate approach in agrometeorological suitability zonation at northeast semiarid plains of Iran
[J].


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}