

0 引言
雾是大量小水滴或冰晶悬浮于近地面空气中造成的水平能见度低于1 000 m的天气现象,能见度(Visibility,VIS)小于等于500 m时被定义为浓雾(宗晨等,2019)。浓雾为豫南地区(南阳、信阳、驻马店三地市)频发的灾害性天气之一,常对铁路运行及交通安全造成重要影响。如2018年11月19日,豫南境内大广高速因大雾发生二十辆车连环相撞,此类交通事故层出不穷。因此对浓雾的准确预报,对减少经济损失、保障人民的健康和生命安全具有极其重要的意义。
我国自20世纪50年代末便开展了对雾的监测预报研究(李子华,2001;Niu et al., 2010;章国材,2016;赵欢等, 2023;王清平等,2024)。最初,预报员通过分析雾形成的气象条件和特征,总结出经验预报法(毛冬艳和杨贵名,2006;蒋大凯等,2007;韦荣等,2022;刘超等,2023),但该方法难以实现空间更为精细和分等级的雾预报。随着数值预报技术的发展,雾的预报方法逐渐客观化。使用数值模式直接输出的能见度或从数值预报产品中筛选相关气象因子构建与能见度相关的预报模型均可获得对雾的预报,其中,后者被称为数值预报产品释用法,借助一些传统统计方法如多元回归法(周须文等,2014)、非线性回归法(周文君等,2016)、逐步回归法(陈健等,2020;邢楠等,2020)等获取的能见度预报相比前者预报效果更优。随着大数据技术的进步,机器学习方法因其出色的自主学习和处理非线性问题的能力,也被应用于预报模型的构建(周永水等,2022;刘杰等,2024)。支持向量机(吴波等,2017)、决策树算法(何东坡等,2023)、BP(Back Propagation)神经网络(刘德等,2005;李沛等,2012;胡海川等,2018;谢超等,2019;文俊鹏等,2021)、长短期记忆神经网络(方楠等,2022)、XGBoost(eXtreme Gradient Boosting)算法(王勇,2019)等多种方法被用于各地区的能见度预报和雾预报。
在多种机器学习算法中,LightGBM(Light Gradient Boosting Machine)是一种以决策树为基础的梯度提升机器学习方法,由微软于2016年开源。相较于传统的树类集成学习方法,如随机森林和XGBoost,LightGBM在处理大数据时展现出更高的训练效率、更低的内存消耗和更高的准确率,其结合了基于梯度的单边采样(Gradient-based One-Side Sampling,GOSS)算法和互斥特征捆绑(Exclusive Feature Bundling,EFB)算法,该方法目前在工业工程(王华勇等,2018)、交通(Wang et al., 2018)等多个领域得到成功应用。在气象领域,谭江红等(2018)、方鸿斌等(2024)基于LightGBM算法建立了湖北省格点气温预报方法,目前已成功业务运行。王志宇(2019)使用LightGBM算法对WRF模式(Weather Research and Forecasting Model)预报的能见度进行订正,建立了上海市大气能见度预报订正模型,明显提升了模式的原始预报精度。目前,LightGBM算法在豫南地区的能见度客观预报方面尚未得到实践与应用。因此,本文利用多源数据对豫南地区浓雾的天气特征进行统计分析,筛选预报因子,基于LightGBM方法构建豫南地区能见度分级预报(Visibility Classification Forecast,VCF)模型,实现豫南国家站能见度的客观分级预报,进而生成豫南浓雾预报产品,以期为豫南地区低能见度浓雾天气的气象服务和灾害预防提供科学依据。
1 资料与方法
用于统计分析和建模训练的数据资料包括:1)豫南地区31个国家级气象站(信阳鸡公山站为高山站,不列入)常规地面观测资料,站点位置见图1;2)欧洲中期天气预报中心(European Centre for Medium-Range Weather Forecasts,ECMWF)的全球气候第五代大气再分析数据集ERA5再分析资料,具体包括经向风U、纬向风V、相对湿度RH、比湿和温度等,水平分辨率为0.25°×0.25°,垂直方向为1 000、950、925、850、700、600、500、400 hPa等8层,从https://cds.climate.copernicus.eu/获取;3)河南省生态环境厅公布的信阳、南阳、驻马店3个环境监测站(图1)逐小时PM2.5质量浓度。以上资料起止时间为2019—2021年。
图1

图1
2019—2021年豫南国家站浓雾频次(红色圆点中心为国家站位置,大小表示频次)、环境监测站(紫色三角形)和地形高度(彩色填色,单位:m)空间分布
Fig.1
The spatial distribution of dense fog frequency at national stations in southern Henan from 2019 to 2021 (the center of the red dot represents the position of the national station, and the size represents the frequency), environmental monitoring station positions (purple triangle) and terrain height (the color shaded, Unit: m)
用于模型检验的数据资料包括:1)ECMWF每日08:00起报的未来36 h的逐3 h预报;2)信阳、南阳、驻马店3个环境监测站每日08:00测得的PM2.5质量浓度。以上资料起止时间为2022年1—3月。文中所有时间均为北京时。
统计分析时以国家站1 h最小VIS≤500 m且不伴随降水判定为“出现浓雾”,进行频次统计;以20:00—20:00为一天(考虑到雾往往在夜间开始生成且持续至次日上午)进行日数统计,一天内有3个及以上国家站出现浓雾定义为一个浓雾日。建模训练时采用双线性插值将逐小时的ERA5再分析资料插值到国家站提取相应物理量,并与该时刻国家站观测数据相匹配,每个国家站的PM2.5质量浓度数据使用该地市的环境站监测值,如驻马店10个国家站均使用驻马店站的PM2.5监测数据,以国家站该时刻的最小能见度等级为预报对象,构建训练数据集。训练数据集剔除了地面观测缺测、异常值时次和因降水导致的VIS≤500 m的时次。模型检验时,同样将ECMWF模式预报采用双线性插值法插值到国家站提取相应预报因子输入模型进行预报。检验使用预报准确率(Accuracy,ACC)、TS评分(Threat score,TS)、召回率(Recall,REC)3种评分方法(Schaefer, 1990;潘留杰等,2014),具体公式如下:
式中:NA、NB、NC、ND分别表示浓雾预报正确的站次数、预报出现浓雾而实况未出现的站次数(空报)、实况出现浓雾而预报未出现的站次数(漏报)、实况和预报均未出现浓雾的站次数。
2 豫南浓雾预报因子选取
2.1 基于物理量分析的预报因子选取
机器学习模型的优劣取决于对天气物理规律的深刻理解和准确把握(周康辉等,2021)。本研究首先对豫南浓雾的空间分布、天气类型及浓雾出现时的物理量特征进行深入分析并选取关键预报因子。
2019—2021年豫南国家站浓雾频次空间分布见图1。结合地形高度来看,豫南西部为南阳盆地,低凹的地形使得盆地内浓雾多发,自西向东逐渐过渡为平原,在山地平原交汇处、驻马店中部浓雾也多发,呈现出一定的地域特征。考虑这一特点将国家站站号重新编码为1—31(stationID)和该站的地形高度(Height)作为预报因子。2019—2021年豫南共159个浓雾日,多发于1月、3月和12月。豫南浓雾在4—9月较为少发,3 a共49个浓雾日,浓雾的站次、空间范围、强度等均偏少偏弱。从浓雾的天气类型分析,以辐射雾为主,占比71%,辐射—平流雾次之,平流雾最少,仅5 d。通过对不同类型浓雾出现时地面要素和高空物理量的分析,选取浓雾天气形成的关键要素如下。
浓雾的形成需要近地面层有充足的水汽。尤其对于辐射雾,其范围和持续时间受低层湿度的影响较大。选取2 m温度露点差(T-Td)2 m、1 000、950、925 hPa等近地面层的相对湿度(RH1000、RH950、RH925)作为反映水汽条件的预报因子。豫南辐射—平流雾的形成同时受边界层内暖湿平流的作用,选取1 000、950、925 hPa水汽通量和(WF1000-925)表示边界层内水汽输送强度。
其次浓雾的形成需要一定的冷却条件,使得近地面降温、水汽凝结形成雾。豫南以辐射雾和辐射—平流雾为主,均受到辐射冷却的作用。中高层偏干的环境有利于辐射冷却,选取850~400 hPa各层的相对湿度(RH850、RH700、RH600、RH500、RH400)反映中上层湿度条件。选取2 m温度(T2 m)和24 h变温(T24 h)反映地面的降温情况。
层结稳定也是浓雾形成的必要条件之一,使得凝结的水汽集中在边界层内形成雾。逆温层是层结稳定度的指标之一。豫南所有浓雾的形成都伴有逆温层,但逆温层高度和强度有所不同。本文以1 000~850 hPa最高温度(Tmax1000-850)与2 m~950 hPa最低温度(Tmin 2 m-950)之差(Tmax1000-850-Tmin 2 m-950)表示逆温强度。其次,边界层内的暖平流加大了与低层的温差,也利于层结稳定,选取950 hPa和925 hPa温度平流和(TD950-925)表示暖平流强度。风场也反映层结稳定度,因此加入700 hPa以下各层UV风场(U700、V700、U850、V850、U925、V925、U1000、V1000)。海平面气压(Mean Sea Level Pressure,MSLP)、3 h变压(P3 h)、24 h变压(P24 h)、10 m风向(WD10 m)、10 m风速(WS10 m)是地面层结状况的反映,大多数浓雾发生在冷高压控制下或地面均压场中,风力微弱。以上均作为天气预报因子加入。
此外,考虑雾形成所需要的凝结核条件,在空气污染加重时,PM2.5等污染物质量浓度的增加对浓雾的形成也有利,本研究加入1 h PM2.5质量浓度作为预报因子。
综上共选取出以下30个预报因子,见表1。
表1 预报因子选取
Tab.1
| 项目 | 预报因子 |
|---|---|
| 地面场要素 | T2 m、T24 h、(T-Td)2 m、WD10 m、WS10 m、MSLP、P3 h、P24 h |
| 高空场要素 | RH1000、RH950、RH925、RH850、RH700、RH600、RH500、RH400 U700、V700、U850、V850、U925、V925、U1000、V1000 WF1000-925、TD950-925 |
| 衍生变量 | Tmax1000-850-Tmin 2 m-950 |
| 其余 | stationID、Height、PM2.5 |
2.2 LightGBM特征重要性排序
在机器学习中,特征选择是提高模型性能和减少过拟合的重要步骤之一。在正式建模前,将以上基于天气学分析选取的预报因子使用LightGBM模型中的特征重要性排名进行了初步试验。将159个浓雾日的逐小时数据输入LightGBM做二分类训练,特征重要性排名如图2,从大到小前十名依次为:RH1000、T2 m、T24 h、RH400、U700、Tmax1000-850-Tmin 2 m-950、MSLP、RH500、PM2.5、RH600。可见模型判断浓雾出现最重要的因素在于近地面相对湿度、温度和变温,其次是RH400,反映中高层湿度和云量。U700、逆温参数Tmax1000-850-Tmin 2 m-950这两者位列其后,均反映层结稳定状况,其后的MSLP反映了近地面稳定度。PM2.5在重要性排名中位列第九,说明在浓雾预报中考虑污染物浓度非常必要,污染物一方面为雾提供了凝结核条件,也一定程度上反映了大气边界层高度和稳定度条件。可见模型给出的特征重要性排名与上述天气学原理分析和实际预报经验基本一致。另外,除(T-Td)2 m的重要性略低外,其余各个特征重要性值之间差别不大,总体来看,选取的预报因子较为合理。
图2

3 VCF模型构建
3.1 预报量定义
表2 能见度分级
Tab.2
| 分级/预报量 | VIS |
|---|---|
| 0 | VIS≤500 m |
| 1 | 500 m<VIS≤1 km |
| 2 | 1 km<VIS≤5 km |
| 3 | 5 km<VIS≤10 km |
| 4 | VIS>10 km |
3.2 训练方法与模型参数
本文使用Python进行机器学习建模。将2019—2021年的逐小时数据作为建模样本,为尽可能增加浓雾日在训练样本中的比例,也为更有针对性的对秋冬季浓雾进行预报训练,本文仅使用浓雾频发的每年1—3月和10—12月的数据(共546 d)。使用豫南地区31个国家站逐小时30个预报因子与同时次的能见度实况等级相匹配,构建训练数据集(共546×24×31=406 224组数据,因地面观测缺测的时次为1 163组、异常值时次446组、因降水导致VIS≤500 m的时次5 916组,质控后共398 699组数据),使用LightGBM方法进行多分类训练。训练过程中,利用遗传进化算法对给定的参数列表字典进行超参数优化,以寻找最优的机器学习参数配置,采用5折CV交叉验证(5-fold Cross-Validation)避免模型过拟合,最终形成VCF模型,并保存模型用于预测。相关使用方法和原理可参考LightGBM(Ke et al.,2017)、scikit-learn(Pedregosa et al.,2012)、tpot(Olson and Moore,2019)等项目文档,表3列出最终使用的模型参数。
表3 VCF模型主要参数
Tab.3
| 参数名称 | 参数简介 | 参数值 |
|---|---|---|
| boosting_type | 弱学习器类型 | gbdt |
| objective | 学习任务及相应的学习目标 | multiclass |
| metric | 用于指定评估指标 | multi_logloss |
| learning_rate | 学习率 | 0.077 |
| num_leaves | 叶子个数 | 80 |
| Max_depth | 最大深度 | 8 |
| min_data_in_leaf | 叶节点样本的最少数量用于防止过拟合 | 12 |
| feature_fraction | 对特征随机采样的比例 | 0.9 |
| bagging_fraction | 每次迭代时用的数据比例 | 0.876 |
4 预报检验
4.1 2022年1—3月浓雾日检验
使用2022年1—3月豫南17个浓雾日的独立样本进行预报检验。检验时使用ECMWF模式每日08:00起报的未来36 h逐3 h预报数据插值到站点提取相应预报因子输入VCF模型,PM2.5质量浓度使用当日08:00环境监测站的实况(经前期统计,在无明显污染传输时,PM2.5质量浓度常在白天下降夜间上升,夜间浓度与08:00基本持平,因此使用08:00 PM2.5质量浓度近似代表),得出豫南31个国家站未来36 h逐3 h能见度分级预报,通过判断预报量是否为“0”得出VCF模型是否预报该站点将出现浓雾,因实际预报业务中在每天下午获取到当日08:00起报的ECMWF预报产品,因此本文重点关注20:00—20:00(即第12~36 h预报)的逐3 h浓雾预报技巧。同时使用ECMWF模式预报的能见度按照表2分级进行对比检验。
图3
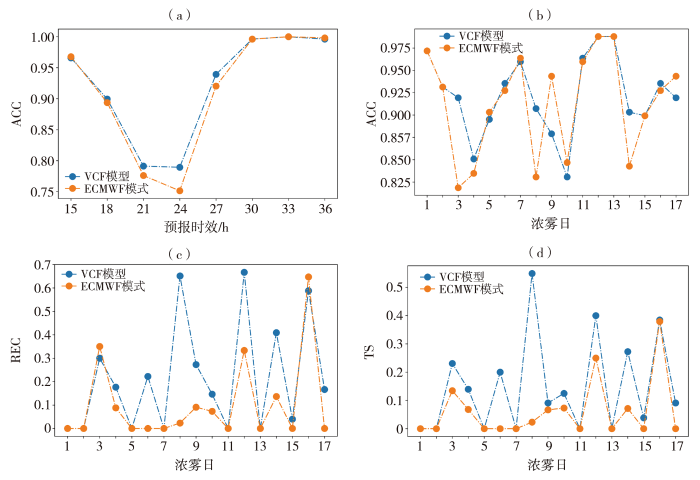
图3
2022年1—3月豫南17个浓雾日不同模型不同预报时效的平均ACC(a)及逐日ACC(b)、REC(c)、TS评分(d)
Fig.3
The average accuracy score of different forecast time periods (a) and daily accuracy score (b), recall score (c) and threat score (d) with different models of 17 dense fog days in southern Henan from January to March 2022
综合各项评分来看,VCF模型对于浓雾的预报提高了REC和TS评分,一定程度上降低了浓雾漏报率,相比ECMWF模式预报技巧有提高。
4.2 个例检验
4.1节对浓雾预报进行了逐时次检验,但在业务预报中,对未来24 h浓雾落区的潜势预报也同样重要,此时并不要求预报时次与出现时次完全相同。因此,使用VCF模型每天预报的20:00—20:00(即第12~36 h预报)最小能见度等级与实况进行对比来检验VCF模型在业务预报中的可用性,同时也对比浓雾的发生时段与预报时段的一致性。
图4

图4
2022年1月16日20:00—17日20:00 (a)、17日20:00—18日20:00 (b)、18日20:00—19日20:00 (c)浓雾预报与实况的空间分布
Fig.4
The spatial distribution of dense fog forecast and observation from 20:00 on January 16 to 20:00 on January 17 (a), from 20:00 on January 17 to 20:00 on January 18 (b), and from 20:00 on January 18 to 20:00 on January 19 (c), 2022
16日夜间,豫南受高空槽后西北气流控制,地面有冷空气南下,自16日22:00开始出现大范围辐射雾,持续至17日11:00。预报浓雾时段为16日20:00—17日08:00,从预报时段和空间位置看与实况均较为吻合[图4(a)],评分较高。17日夜间,高空仍受槽后西北气流控制,边界层内西南风增强,925 hPa以下湿度增大,地面气压降低,18日04:00—10:00豫南东部出现辐射平流雾。从图4(b)看,预报浓雾区域也主要位于豫南东部,但具体站点与实况有差异,导致TS评分较低,但预报站点在实况的临近县区,预报时段为18日02:00—08:00,与实况较吻合,对实际预报仍有一定指示意义。18日夜间,新一股冷空气南下,整层受西北风控制,豫南再次出现辐射雾,出现时间在18日23:00—19日12:00。预报时段在18日20:00—19日08:00,持续时间偏短,对比空间范围来看,预报的范围也略偏小[图4(c)],TS评分也不高。
从以上分析可见,VCF模型生成的20:00—20:00豫南浓雾预报产品可以对豫南当日夜间至次日的浓雾落区预报提供重要参考。
5 结论与讨论
本研究利用2019—2021年国家气象站常规地面观测、欧洲中期天气预报中心ERA5再分析资料和环境监测站数据对豫南区域性浓雾日进行了统计分析和物理量诊断,选取30个浓雾预报因子,基于LightGBM机器学习方法建立能见度分级预报(VCF)模型,通过输入ECMWF模式08:00起报资料和08:00 PM2.5质量浓度获取豫南未来36 h逐3 h能见度分级客观预报,从而得到20:00—20:00豫南浓雾客观预报产品。使用2022年1—3月的独立样本进行预报检验,得出以下主要结论。
1)VCF模型在2022年1—3月浓雾天气预报检验中预报效果良好,对凌晨至上午的浓雾预报有一定提高。豫南17个浓雾日的各项评分中,TS评分有平稳的提高,3 d的REC高达0.5以上,相比ECMWF模式降低了漏报率,提高了预报技巧。
2)对2022年1月16—19日豫南区域性浓雾个例检验显示,VCF模型生成的20:00—20:00豫南浓雾预报产品可为浓雾落区预报提供重要参考,预报浓雾时段与实况也较为一致,均出现在夜间。可见VCF模型可为浓雾的业务预报提供一定技术支撑。
能见度受气象条件、排放源、复杂下垫面等多种因素的影响,具有较强的非线性,变化复杂,本研究使用了大量基本气象要素,下一步计划加入边界层高度、静稳指数等组合因子及其他污染数据进行试验。现有的一些研究结论表明,ECMWF模式对近地面要素的预报存在一定偏差,尤其是近地面湿度状况,因此尝试将客观订正后的2 m温度等智能网格预报产品输入模型进行计算,有望进一步提高豫南浓雾的预报技巧。
参考文献
数值天气预报检验方法研究进展
[J].
数值天气预报检验是改进及应用数值模式的重要环节。近年来,模式检验中的观念不断更新,适用于不同预报产品及不同用户需求的模式检验方法也不断涌现。首先简单回顾了以列联表为基础的传统的模式检验方法。其次重点总结了伴随高分辨率数值预报而出现的空间诊断检验技术,按照检验目的的不同,诊断方法可以归纳为:①基于滤波技术的分辨模式在不同时空尺度上预报能力的邻域法、尺度分离法;②利用位移偏差诊断模式预报位置、面积、方位、轴角等与观测差异的属性判别法、变形评估法。然后阐述了集合样本成员的概率分布函数(PDF)、集合预报与观测概率分布函数相似程度、事件发生的概率预报等集合预报检验方法。最后论述了空间诊断技术、集合预报检验方法的适用领域,并讨论了模式检验中存在的一些问题及未来的发展方向。
LightGBM: A highly efficient gradient boosting decision tree
[C]//
Fog research in China: An overview
[J].
TPOT: A tree-based pipeline optimization tool for automating machine learning
[M]//
Scikit-learn: Machine learning in Python
[J].
The critical success index as an indicator of warning skill
[J].
Detecting transportation modes based on LightGBM classifier from GPS trajectory data
[C]//


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}