

0 引言
干旱成因分析是预测干旱的关键,国内外学者已经进行了不少有关干旱物理机制方面的研究。干旱一般由降水异常偏少造成,而降水多少通常与海洋或陆面热力、动力异常引起的大气环流异常有关(袁星等,2020;张强等,2020)。研究表明,欧亚大陆与青藏高原热力异常可以改变海陆热力差异,影响季风的产生和强弱,进而决定中国夏季降水的空间格局(Ding et al.,2014;丁一汇等,2018)。热带印度洋东南部海温异常增暖加强哈得来环流,导致中国南方出现异常下沉运动,从而造成该地区夏季降水异常偏少(Huo and Jin,2016)。北大西洋多年代际振荡则通过激发遥相关波列影响东亚地区降水,其正位相将导致长江及其以南地区降水偏少(Si and Ding,2016)。不同纬度的大气环流系统本身及其相互作用也是引起降水变化的重要因素(张玲和智协飞,2010;张强等,2024)。例如,当西太平洋副热带高压面积偏大、强度偏强、位置偏西,其控制区内的异常下沉运动以及偏弱的水汽输送将导致高温干旱发生(王文等,2017;夏扬和徐海明,2017;李忆平等,2022)。当北方极涡强度偏弱、面积偏小时,北方冷空气势力偏弱,加上中纬度地区环流平直,使得冷空气无法与南方暖湿气流交汇产生降水,会造成降水偏少现象(王海燕等,2019;高琦和徐明,2021)。
为更好地建立干旱预测模型,除了选择合适的预测因子,高效的预测方法也至关重要。之前利用简单传统统计预测方法构建的干旱预测模型逐渐不能满足人们对干旱预测准确率的期望。例如基于多元线性回归方法建立的线性、对数型、幂函数型和指数型4种西南地区秋季干旱预测模型中,对数模型在验证期内准确率达75.00%,而其他3个模型均仅为62.50%(董亮等,2014)。当前,随着人工智能领域的兴起,机器学习算法快速发展,相比传统统计预测方法更具高效性和可靠性。机器学习算法中分类回归树算法解释性强,分类规则直观易懂,剪枝处理也可以有效避免过拟合(官雨洁等,2018;郑力嘉和宋冰,2023),同时随机森林算法作为一种基于决策树的集成方法,也具有很好的泛化能力(方匡南等,2011;黄海新等,2016)。当前已有学者利用机器学习算法在提高干旱预测准确率和预见期方面取得进展:如王伟等(2016)基于多项气候因子数据和分类回归树算法建立河南商丘站干旱预测模型,其预报准确率高达91.67%;吴晶等(2016)采用随机森林算法预测淮河流域气象站各月干旱等级,发现机器学习算法模型预测平均准确率明显高于气候系统预报;殷浩等(2021)结合全球气候模式预报与机器学习算法构建动力—统计预测模型,不仅能提升春季和夏季干旱预测技巧,也能延长华北、华中及华南地区干旱事件预见期。
湖北省大部属亚热带季风气候,降水充沛且梅雨明显,但由于降水存在季节分配不均和年际变率大等特点,导致湖北省干旱多发于夏季(邵末兰和向纯怡,2009;郑治斌和刘可群,2020)。为提高应对干旱灾害的能力,需要建立湖北省夏季干旱预测模型。研究表明机器学习算法在干旱预测方面有良好的应用前景(王伟等,2016;吴晶等,2016;殷浩等,2021)。然而,当前研究主要围绕其他地区展开,较少应用于湖北省夏季干旱预测中,并且不同地区的干旱预测模型存在差异。因此,本文通过分类回归树算法和随机森林算法分别建立湖北省夏季(6—8月)干旱预测模型,并对两种机器学习算法预测效果进行对比检验,以期为湖北干旱预测提供多样性的选择,揭示不同机器学习算法在同一区域的预测效果差异,从而优化预测模型的选择与应用。
1 资料与方法
1.1 资料
气象站点观测数据来源于湖北省气象局内网气象预报服务业务一体化平台,剔除时间序列不完整的站点数据后,选用湖北省70个国家气象站1960—2022年逐月平均温度、降水量等气象要素进行研究,该资料经过了严格的质量控制,具有很好的连续性和完整性。气候因子数据主要来自国家气候中心和美国国家海洋和大气管理局(National Oceanic and Atmospheric Administration,NOAA)。选取国家气候中心网站(http://cmdp.ncc-cma.net/Monitoring/cn_index_130.php)1960—2022年88项大气环流指数和26项海温指数,以及NOAA网站(https://psl.noaa.gov/data/climateindices/list/)提供的北大西洋多年代际振荡(Atlantic Multidecadal Oscillation,AMO)、北大西洋涛动(North Atlantic Oscillation,NAO)、准两年振荡(Quasi-Biennial Oscillation,QBO)等多项指数进行研究。本文使用标准化降水蒸散指数(Standardized Precipitation Evapotranspiration Index,SPEI)来表征干旱,该指数对中国区域干旱监测具有较好的适用性(王文举等,2012;庄少伟等,2013;赵林等,2015;谢南茜等;2023)。由于本文聚焦于夏季(6—8月)的干旱预测,因此使用3个月尺度的标准化降水蒸散指数,可以较好地反映季节尺度的干旱情况。
1.2 方法
1.2.1 标准化降水蒸散指数
表1 基于SPEI的干旱划分标准
Tab.1
| SPEI | 干旱等级 | 是否干旱 |
|---|---|---|
| -0.5<SPEI | 无旱 | 否 |
| -1.0<SPEI≤-0.5 | 轻旱 | 是 |
| -1.5<SPEI≤-1.0 | 中旱 | 是 |
| -2.0<SPEI≤-1.5 | 重旱 | 是 |
| SPEI≤-2.0 | 特旱 | 是 |
1.2.2 机器学习算法
1.2.2.1 分类回归树算法
假设样本集合D包含K个类别,其中样本属于第k(k=1,2,3,…,K)类的概率为Pk,则集合D的基尼指数gini(D)为:
在构建分类决策树过程中,依据特征变量A的第i个值对样本集合D进行分类,得到集合D1和D2,此时集合D基尼指数变为:
式中:n1、n2、n分别为集合D1、D2、D的样本数量。
值得注意的是,当数据过度训练时,得到的决策树会十分复杂且庞大,极易导致过拟合,使得模型在训练集中有很好表现,而在从未见过的测试集中分类能力显著下降。为了防止过拟合,可以通过剪枝处理保留最重要的特征分类标准(郑力嘉和宋冰,2023)。
1.2.2.2 随机森林算法
首先通过从原始数据集S中有放回地自举抽样得到N个新的数据集(S1,S2,S3,…,SN),然后基于每个新的数据集分别建立决策树(h1,h2,h3,…,hN),其中每颗决策树的分裂节点是从对应的新数据集所含特征中随机选择产生,建立的多棵决策树构成一个随机森林,最后将多棵决策树预测结果以投票方式进行整合得到最终预测结果。
由于经过自举抽样得到的新数据集中会出现部分原始数据未被抽中的情况,这些未抽中的数据称为袋外(Out Of Bag,OOB)数据,可以用来估计决策树的泛化误差。随机森林中所有决策树OOB误差的平均值能很好地体现随机森林算法模型的泛化能力(吴晶等,2016)。
2 湖北省夏季干旱的时空演变特征和影响因子分析
2.1 时空演变特征
图1为1960—2022年湖北省夏季SPEI年际变化。可以看出,干旱指数变化率为0.05 (10 a)-1,呈微弱上升趋势且年际变化较大。分析极端年份发现,1966年、1972年和2022年夏季湖北省发生了严重干旱事件,而1969年、1980年和2020年湖北省夏季偏湿。20世纪60年代至70年代、21世纪初湖北省夏季SPEI≤-0.5的年份远多于20世纪80年代至90年代末。统计发现1960—2022年湖北省夏季共发生干旱20 a,无旱43 a,其中1960—1979年有8 a干旱、1980—1999年有4 a干旱、2000—2022年有8 a干旱,表明1960—2022年湖北省夏季大致呈现“干旱—湿润—干旱”的变化特征。
图1
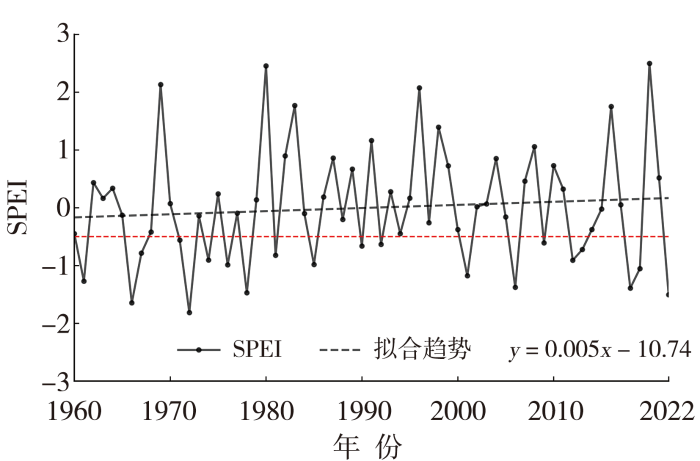
图1
1960—2022年湖北省夏季SPEI年际变化
(红色虚线为是否干旱的临界线)
Fig.1
The inter-annual variation of summer SPEI in Hubei Province from 1960 to 2022
(The red dashed line denotes the critical threshold of drought)
经验正交函数(Empirical Orthogonal Function,EOF)能把随时间变化的变量场分解为不随时间变化的空间函数和只依赖时间变化的时间函数,用于研究数据主要变化模态及时间变化规律(余兴湛等,2022)。本文利用EOF分解方法分析1960—2022年湖北省夏季SPEI的时空特征,得到前3个模态方差贡献率分别为55.9%、12.7%和5.5%,累积方差贡献率可达70%以上,能较好地表征湖北省夏季干旱的整体情况。EOF第1模态空间分布表明湖北省夏季干湿状态空间分布全区一致且均为负值[图2(a)],对应时间系数整体呈“正—负—正”的变化[图2(d)],即湖北省夏季呈现“干旱—湿润—干旱”的变化,这与之前结论一致;EOF第2空间模态中鄂东南为负值中心,鄂北岗地为正值中心,东南向西北整体呈现由负变正的变化趋势[图2(b)],对应时间系数在1990年后有“负—正—负”的变化趋势[图2(e)],即1990年后湖北省干旱多发于鄂北岗地一带;EOF第3空间模态中鄂中、鄂东北与鄂西北、鄂东南干旱变化情况相反[图2(c)],对应时间系数多波动,未出现长时间持续正值或者负值的情况[图2(f)]。综合来看,湖北省干旱时空变化特征复杂,建立湖北省夏季干旱预测模型十分必要。
图2
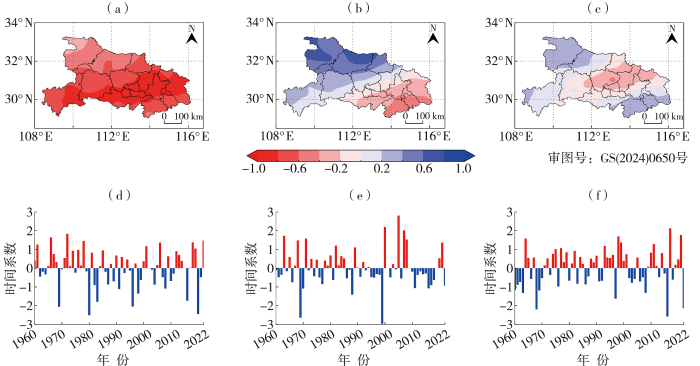
图2
1960—2022年湖北省夏季SPEI的EOF分解的第1(a、d)、第2(b、e)和第3(c、f)模态空间分布(a、b、c)及其对应的时间系数(d、e、f)
Fig.2
The spatial distribution (a, b, c) and their corresponding time coefficients (d, e, f) of the first (a, d), second (b, e), and third (c, f) modes by EOF decomposition of the summer SPEI in Hubei Province from 1960 to 2022
2.2 影响因子的选择和分析
在特征工程中,数据和特征往往决定了机器学习的上限,选择好的特征变量(影响因子)对湖北省夏季干旱预测模型尤为重要。特征选择一般包含3类方法,分别是“过滤法”、“包裹法”、“嵌入法”,其中“过滤法”主要依据发散性或者相关性对各特征进行评分,进而通过设定阈值进行特征选择,从而得到与预测目标紧密相关的特征,例如方差分析选择和互信息选择;“包裹法”指从大量特征中搜索一个特征子集使得预测模型效果最优,例如递归特征消除法;“嵌入法”指根据模型中各特征重要性进行选择,例如基于L1范数选择、随机森林选择(Guyon and Elisseeff,2003)。本文根据方差分析、互信息、递归特征消除法、递归特征消除法和5折交叉验证、基于L1范数、随机森林特征选择方法得到了6个特征子集,然后筛选6个特征子集中出现5次及以上的特征作为预测模型输入变量。
结合以上多种特征选择方法,从国家气候中心和NOAA网站获取的大气环流和海温指数中筛选出11个与湖北省夏季干旱紧密相关的影响因子。由表2可知,夏季热带南大西洋海温指数、北大西洋副高北界位置指数、亚洲纬向环流指数、AMO指数与湖北省同期SPEI为正相关,即当上述指数为正异常时,SPEI增大,湖北省夏季偏湿;而亲潮区海温指数、西风漂流区海温指数、西太平洋副高脊线位置指数、北美副高脊线位置指数、亚洲区极涡面积指数、斯堪的纳维亚遥相关型指数和NAO与夏季SPEI呈负相关,即该指数为正异常时,SPEI减小,湖北省夏季偏干。例如,西太平洋副高脊线位置指数与湖北省夏季SPEI相关系数为-0.37,即当夏季西太平洋副高脊线异常偏北时,湖北省受西太平洋副高控制,有强烈的下沉逆温,使低层水汽难以成云致雨,易发生干旱(郝立生等,2022)。另外,西太平洋副高脊线位置指数、北大西洋副高北界位置指数、亚洲区极涡面积指数、斯堪的纳维亚遥相关型指数以及AMO指数与夏季SPEI的相关性均通过α=0.05的显著性检验,说明以上变量与湖北省夏季干旱显著相关。
表2 1960—2022年湖北省夏季干旱影响因子定义及其与同期SPEI的相关系数
Tab.2
| 特征编号 | 影响因子 | 定义 | 相关 系数 |
|---|---|---|---|
| 1 | 热带南大西洋海温指数 | 30°W—10°E、20°S—0°区域内海表温度距平的区域平均值 | 0.19 |
| 2 | 亲潮区海温指数 | 165°E—175°E、40°N—45°N区域内海表温度距平的区域平均值 | -0.15 |
| 3 | 西风漂流区海温指数 | 160°E—160°W、35°N—45°N区域内海表温度距平的区域平均值 | -0.09 |
| 4 | 西太平洋副高脊线位置指数 | 110°E—150°E、10°N—60°N区域内500 hPa高度场逐条经线上副热带高压中心位置所在纬度的平均值 | -0.37** |
| 5 | 北美副高脊线位置指数 | 110°W—60°W、10°N—60°N区域内500 hPa高度场逐条经线上副热带高压中心位置所在纬度的平均值 | -0.24* |
| 6 | 北大西洋副高北界位置指数 | 55°W—25°W、10°N—60°N区域内500 hPa高度场逐条经线上副热带高压北侧5 880 gpm等值线所在纬度的平均值 | 0.26** |
| 7 | 亚洲区极涡面积指数 | 北半球60°E—150°E区域内500 hPa高度场极涡南界特征等高线以北所包围的扇形面积 | -0.30** |
| 8 | 亚洲纬向环流指数 | 60°E—150°E、45°N—65°N区域内500 hPa高度场以30个经度为间隔划分为3个区,计算平均纬向指数 | 0.07 |
| 9 | 斯堪的纳维亚遥相关型指数 | 0°—360°、20°N—90°N区域内,标准化500 hPa高度场经验正交函数分析所得的第九模态的时间系数 | -0.32** |
| 10 | AMO | 80°W—0°、0°—60°N区域内平均的海表面温度距平 | 0.26** |
| 11 | NAO | 90°W—50°E、20°N—85°N大西洋地区海平面气压距平场的经验正交函数分解第一主成分 | -0.24* |
注:**、*分别表示相关系数通过α=0.05、α=0.1的显著性检验。
3 湖北省夏季干旱预测模型的构建与检验
建立湖北省夏季干旱预测模型,首先需要明确预测模型的输入变量和目标变量,将特征选择处理后的11个指数作为输入变量,是否干旱作为预测目标。其中输入变量建模时是实况数据,进行预测时可用数值模式预报数据。随机选取47 a数据作为训练集用于模型的构建,剩余16 a(1962、1963、1966、1977、1979、1980、1981、1983、1986、1987、1991、1995、1997、1999、2001、2013年)作为测试集用于评估模型效果,训练集与测试集中样本数量之比约为3:1。
3.1 基于分类回归树算法的湖北省夏季干旱预测模型构建与检验
利用网格搜索和5折交叉验证方法对分类回归树预测模型参数调优,得到最优参数组合:max_depth=7、criterion=“gini”、min_samples_leaf=2、min_samples_split=2,即最大深度为7、节点划分标准选择“gini”、叶子节点含有最少样本数为2、节点可分的最小样本数为2。基于该参数组合建立的决策树共包含14条分类规则集(图3)。决策树根节点从NAO指数开始,表示为当“NAO≤0.48”时,训练集47个样本(“samples=47”)中无旱和干旱样本分别为31个和16个(“value=[31,16]”),当前分类为无旱(“class=无旱”),此时gini=0.45,其他节点与该节点表述相同。对于每条分类规则集,从根节点依次进行条件判别直至叶节点,以最右侧两条分类规则为例:(1)当“NAO>0.48”时,继续判断当“亚洲纬向环流指数>8.58”时,最后预测该样本为无旱;(2)当“NAO>0.48”,且“亚洲纬向环流指数≤8.58”时,继续判断“亚洲区极涡面积指数≤16.43”是否成立,如果成立,需要继续进行条件判别;如果不成立,则预测该样本为干旱。其他规则集依此类推。
图3
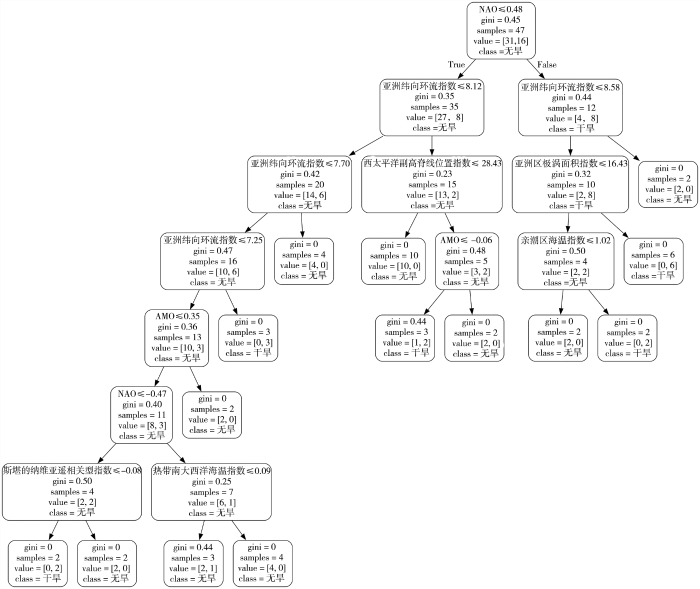
图3
基于分类回归树算法的湖北省夏季干旱预测模型
Fig.3
Prediction model for summer drought in Hubei Province based on classification and regression tree algorithm
选用准确性作为评估模型预测效果的指标,发现基于分类回归树算法的湖北省夏季干旱预测模型在训练集和测试集上预报准确率分别为96%和88%。图4为该模型的混淆矩阵检验结果,可以看出训练集中实际无旱年份为31 a,其中正确预测30 a,仅错误预测1 a;实际干旱年份共16 a,预测错误1 a,正确15 a;测试集中实际无旱年份12 a,正确预测12 a,无预测错误年份;实际干旱年份共4 a,预测错误2 a,正确2 a。以上结果表明,基于分类回归树算法建立的预测模型对于湖北省夏季是否干旱有较好的预报能力,特别是对无旱事件。
图4
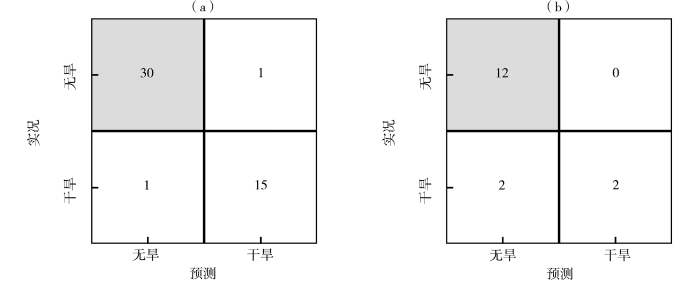
图4
分类回归树算法建模中训练集(a)和测试集(b)的混淆矩阵
Fig.4
The confusion matrix of training set (a) and test set (b) in classification and regression tree algorithm model
为进一步检验模型预测能力,表3列出测试集中分类回归树算法预测干旱情况与实况对比。可以看出,分类回归树预测模型正确预测出2001和2013年湖北省夏季干旱,而漏报了1966、1981年干旱,同时该模型对无旱事件具备很好的预测能力,成功预测出1962、1963、1977、1979、1980、1983、1986、1987、1991、1995、1997、1999年湖北省夏季无旱,且无一错报。值得注意的是,该模型对湖北省夏季干旱事件的预测存在一定不确定性。其中1966、1981、2001、2013年湖北省夏季分别发生重旱、轻旱、中旱、轻旱,可知该模型能够对轻旱和中旱事件有一定的预测能力,而对于极端干旱预测能力较差,这可能是因为模型训练过程中极端干旱样本数量太少导致模型对极端干旱事件训练不充分而造成。
表3 测试集中分类回归树算法和随机森林算法预测干旱情况与实况对比
Tab.3
| 年份 | 分类回归树算法预测 | 随机森林算法预测 | 实况 |
|---|---|---|---|
| 1962 | 无旱 | 无旱 | 无旱 |
| 1963 | 无旱 | 无旱 | 无旱 |
| 1966 | 无旱 | 无旱 | 干旱 |
| 1977 | 无旱 | 无旱 | 无旱 |
| 1979 | 无旱 | 无旱 | 无旱 |
| 1980 | 无旱 | 无旱 | 无旱 |
| 1981 | 无旱 | 无旱 | 干旱 |
| 1983 | 无旱 | 无旱 | 无旱 |
| 1986 | 无旱 | 无旱 | 无旱 |
| 1987 | 无旱 | 无旱 | 无旱 |
| 1991 | 无旱 | 无旱 | 无旱 |
| 1995 | 无旱 | 无旱 | 无旱 |
| 1997 | 无旱 | 无旱 | 无旱 |
| 1999 | 无旱 | 无旱 | 无旱 |
| 2001 | 干旱 | 无旱 | 干旱 |
| 2013 | 干旱 | 干旱 | 干旱 |
3.2 基于随机森林算法的湖北省夏季干旱预测模型构建与检验
随机森林是一种基于决策树的集成学习算法,在分类预测问题中表现出色,得到了广泛应用(吕红燕和冯倩,2019)。利用网格搜索和5折交叉验证方法对随机森林预测模型进行多次调参,得到最优参数组合:n_estimators=25、max_depth=8、min_samples_leaf=2、min_samples_split=5,即决策树个数为25、决策树最大深度为8、叶子节点含有最少样本数为2、节点可分的最小样本数为5。基于该参数组合建立的随机森林干旱预测模型在训练集和测试集上预报准确率分别为94%和81%,OOB平均准确率为79%。其中,在训练集中实际无旱年份为31 a,正确预测31 a,无错误预测年份;实际干旱年份共16 a,预测错误3 a,正确13 a。测试集中实际无旱年份12 a,均正确预测;实际干旱年份共4 a,预测错误3 a,正确1 a(图5)。与分类回归树预测模型相比,随机森林算法在相同训练集和测试集上预报准确率略低,主要表现在随机森林预测模型对干旱事件的预测能力低于分类回归树预测模型,但对于无旱事件两个机器学习算法预测模型均有较好的预测能力。
图5
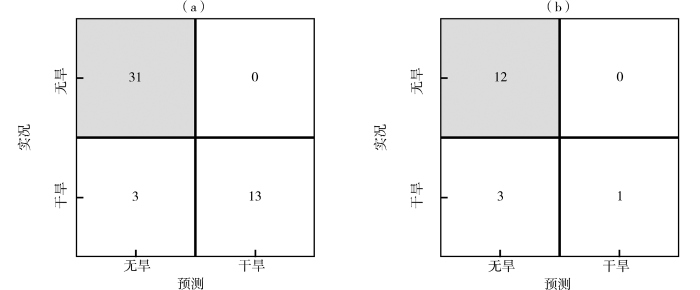
图5
随机森林算法建模中训练集(a)和测试集(b)的混淆矩阵
Fig.5
The confusion matrix of training set (a) and test set (b) in random forest algorithm model
对比测试集中随机森林算法预测值与实况可知(表3),随机森林预测模型正确预测出2013年湖北省夏季干旱,而漏报了1966、1981和2001年干旱,表明该模型对湖北省夏季轻旱事件有一定的预报能力,但对中旱及以上干旱的预测能力有待提高。对于无旱事件,模型能正确预测出测试集中所有无旱年份且无一错报。随机森林预测模型对无旱事件的预测能力明显高于干旱事件。比较机器学习算法与业务发布预测整体水平(表4),受年份资料限制使用2011—2022年评估业务预测发布效果,期间业务发布准确率为66.7%;而分类回归树和随机森林算法预测1960—2022年准确率分别达93.7%和90.5%,较业务发布预测有明显提升。
表4 2011—2022年湖北省实况干旱与两种机器学习算法预测、业务发布预测对比
Tab.4
| 年份 | 分类回归树算法预测 | 随机森林算法预测 | 业务发布预测 | 实况 |
|---|---|---|---|---|
| 2011 | 无旱 | 无旱 | 无旱 | 无旱 |
| 2012 | 干旱 | 干旱 | 干旱 | 干旱 |
| 2013 | 干旱 | 干旱 | 干旱 | 干旱 |
| 2014 | 无旱 | 无旱 | 无旱 | 无旱 |
| 2015 | 无旱 | 无旱 | 无旱 | 无旱 |
| 2016 | 无旱 | 无旱 | 无旱 | 无旱 |
| 2017 | 无旱 | 无旱 | 无旱 | 无旱 |
| 2018 | 干旱 | 干旱 | 干旱 | 干旱 |
| 2019 | 干旱 | 无旱 | 无旱 | 干旱 |
| 2020 | 无旱 | 无旱 | 干旱 | 无旱 |
| 2021 | 无旱 | 无旱 | 干旱 | 无旱 |
| 2022 | 干旱 | 干旱 | 无旱 | 干旱 |
进一步探索基于分类回归树算法和随机森林算法的湖北省夏季干旱预测模型,图6为两个模型中各特征的重要性得分,按从大到小排序,分类回归树预测模型中依次是亚洲纬向环流指数、NAO、亲潮区海温指数、斯堪的纳维亚遥相关型指数、AMO、亚洲区极涡面积指数、西太平洋副高脊线位置指数、热带南大西洋海温指数,而西风漂流区海温指数、北美副高脊线位置指数和北大西洋副高北界位置指数得分不明显;随机森林算法中依次为亚洲纬向环流指数、亚洲区极涡面积指数、NAO、AMO、北美副高脊线位置指数、亲潮区海温指数、热带南大西洋海温指数、北大西洋副高北界位置指数、斯堪的纳维亚遥相关型指数、西风漂流区海温指数、西太平洋副高脊线位置指数。对比可知,两种机器学习算法预测模型中各特征重要性得分存在差异,但两种机器学习算法预测模型都考虑到亚洲纬向环流指数,且将其重要性得分均排在首位。亚洲纬向环流指数涉及60°E—150°E、45°N—65°N区域内500 hPa高度场的演变,该指数反映了高空槽脊的变化,而高空槽脊本身的变化及与其他天气系统的相互作用是业务工作中降水预报的重要参考,进而也对干旱影响很大。
图6
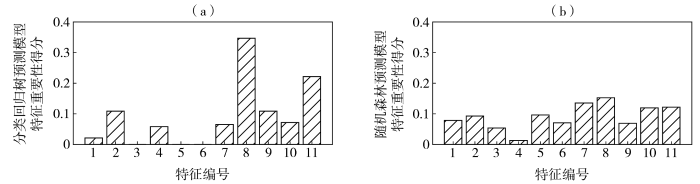
图6
分类回归树(a)和随机森林(b)预测模型中各特征的重要性得分
(特征编号对应
Fig.6
Importance scores of features in the prediction model based on classification and regression tree (a) and random forest (b)
(The number of features corresponds to the influencing factors in
4 结论与讨论
本文选取与湖北省夏季干旱紧密相关的大气环流和海温指数作为输入变量,是否干旱为目标变量,基于分类回归树算法和随机森林算法分别建立湖北省夏季干旱预测模型,并对模型预测效果进行检验分析,得到以下主要结论。
1)1960—2022年湖北省夏季平均SPEI呈微弱上升趋势且年际变化较大。期间湖北省夏季发生干旱共20 a,43 a为无旱,干旱多发于20世纪60年代至70年代以及21世纪初。湖北省夏季干旱指数EOF分解前3个模态累积方差贡献率可达70%以上,其中第1模态占比55.9%,空间分布具有全区一致性,且湖北省干旱随时间呈现“干旱—湿润—干旱”的变化特征。
2)采用特征选择方法从多项大气环流和海温指数中筛选出11个作为输入变量,是否干旱作为目标变量,基于分类回归树算法构建湖北省夏季干旱预测模型得到14条分类规则集,其在训练集和测试集上预报准确率分别为96%和88%;随机森林预测模型准确率分别为94%(训练集)和81%(测试集)。这两个模型对湖北省夏季是否干旱都具有较好的预测能力,其中随机森林算法对干旱事件的预测能力略低于分类回归树算法,但其预测效果更稳定。
3)分类回归树和随机森林预测模型中各特征重要性的考量存在差异,但两个机器学习算法预测模型都将亚洲纬向环流指数的重要性排在首位,说明该指数对湖北省夏季干旱预测十分重要。
本研究基于分类回归树算法和随机森林算法从分类角度分别建立了湖北省夏季干旱预测模型,相比于业务发布预报准确率有所提升,可以为干旱预测提供技术支撑。其中分类回归树算法相比随机森林算法预测效果好,但一定程度上会受训练样本影响,具有不确定性;随机森林算法基于多个分类器进行干旱预测更具稳定性。湖北省夏季干旱以轻旱和中旱为主,高级别干旱样本数量有限,不利于预测模型的构建,造成模型对极端干旱事件预测能力弱。当前建立预测模型主要是定性预报出干旱是否发生,未解决湖北省夏季干旱强度以及空间分布的预测问题,未来可以基于深度学习算法或者集成算法从回归角度对干旱指数进行定量预测;通过对每个站点建立干旱预测模型,从而预测干旱空间分布,这将进一步提升气象服务水平,对防灾减灾具有积极意义。
参考文献
气候变化背景下湖北省高温干旱复合灾害变化特征
[J].
全球气候变化造成的极端气候事件频发已成为科学界和人类社会共同面临的挑战。气候变化驱动因素多样,时空过程复杂,全球不同区域存在显著差异。基于1961—2022年湖北省76个国家气象站逐日降水、气温等观测数据,根据区域性高温过程监测指标和区域性干旱过程监测评估方法,对湖北省1961年以来的区域性高温和干旱事件进行识别,在此基础上分析事件发生频率、持续时间、强度及其影响的变化特征。结果表明:区域性高温事件趋多增强且有连年发生的趋势;区域性干旱事件频次变化趋势不显著,但呈现群发、连发和重发特征;高温干旱复合事件有显著增加、间隔缩短的趋势。2022年夏季高温过程综合强度为1961年以来最强,与长江流域性干旱叠加,产生了从气象干旱到水文干旱、农业干旱和社会经济干旱的链式复杂影响。在全球变暖背景下,湖北省极端高温和干旱及其复合事件频发可能成为气候新常态,亟需加强极端事件的成因及其灾害风险评估研究,提高应对极端和复合型灾害的能力。
2022年长江中下游夏季异常干旱高温事件之环流异常特征
[J].2022年夏季长江流域发生了建国以来最为严重的干旱高温气候事件,对当地工农业生产、居民生活、生态安全等造成严重影响。为深入认识这次干旱高温气候事件发生的原因和改进气候预测技术,利用1951—2022年2400多测站气温、降水数据和NCEP/NCAR再分析数据等资料,采用T-N波作用通量、视热源Q1(Q2)诊断和合成分析、距平分析等方法,从大气环流异常的角度进行综合分析。主要结论如下:(1)2022年夏季,500 hPa源自北大西洋地区的扰动异常偏强,在沿中高纬西风带向东传播时引发了明显的大槽大脊活动,波动能量主要沿西风带向东传播,没有出现在东亚向东南方向传播的特征,造成冷空气活动位置偏北,很难影响到长江流域。(2)2022年夏季,500 hPa高度场在青藏高原上空出现明显正距平扰动,尤其8月扰动进一步加强,东移到长江流域,诱发西北太平洋副热带高压西伸,使得副热带高压呈现东西带状分布。副热带高压(简称“副高”)西部完全控制了长江流域地区,一方面副高阻挡了北方冷空气南下,另一方面副高长时间维持下沉运动,不利于降水发生,有利于下沉增温。(3)2022年夏季,热带对流区(视热源)位置异常偏南到赤道以南(气候态在5°N—20°N),有两方面影响:一是造成哈德来经圈环流(Hadley Cell)上升支异常偏南,长江流域在8月为异常下沉区,不利于降水发生,有利于下沉增温效应的出现;另一方面造成2022年夏季亚洲热带夏季风偏弱、东亚副热带夏季风偏强,低频信号向长江中下游传播明显偏弱,这些都不利于长江中下游降水过程的发生。(4)高纬、中低纬、低纬热带地区环流异常协同作用造成2022年长江流域夏季出现异常的干旱高温气候事件。要预测长江流域夏季降水或高温干旱,需提前关注500 hPa北大西洋地区扰动信号的发生及未来传播特征,青藏高原上空高度场扰动的发生及移动特征,热带对流(热源)位置变化及伴随的热带夏季风强度变化、低频信号的传播特征等。
2022年夏季长江流域重大干旱特征及其成因研究
[J].干旱是影响范围最广的自然灾害之一。2022年夏季发生在长江流域的异常高温干旱事件不仅强度大,而且持续时间长,是一次罕见的重大干旱事件,对我国的社会经济造成了十分严重的影响。鉴于这次事件的极端性,本文在客观分析此次事件演变特征的基础上,揭示大气环流和外强迫异常对此次高温干旱的可能影响。研究发现,气象干旱指数及土壤湿度监测结果一致表明本次旱情从6月开始出现,7月迅速发展,进入8月后范围进一步扩展、强度进一步加剧。与此同时,流域内整体气温偏高,部分地区高温日数超过40 d。此外,夏季整个流域的蒸散量距平是1960年以来的历史第二高值(仅次于2013年高温伏旱),进一步加剧了长江流域的水分亏缺程度。从环流特征来看,夏季西太平洋副热带高压异常偏强西伸、极涡面积偏小及强度偏弱、南亚高压偏强东移,共同导致长江流域的水汽输送条件偏弱、下沉气流盛行,使得整体条件不利于降水发生。而前期拉尼娜事件的持续、印度洋偶极子负位相的出现以及春季青藏高原西北部积雪负异常的持续,可能是导致今年夏季环流异常的主要外强迫因子。
我国气象干旱研究进展评述
[J].近几十年来,在全球变化和社会经济高速发展的影响下,全球环境问题尤为突出。其中最为严峻的问题之一是干旱的频繁发生。干旱已经成为全球性的问题,由干旱,尤其是重大干旱灾害所引起的水资源匮乏、粮食危机、生态恶化( 如荒漠化等) ,直接威胁到国家的长期粮食安全和社会稳定。针对这些问题,本文介绍了国家对干旱研究的需求和近年来在干旱研究领域的主要科技进展,提出了目前干旱研究领域存在争议的问题、以及面对国家需求应解决的关键科学问题。并对未来5 ~ 10 a该领域的发展趋势进行了简要分析。
21世纪以来干旱研究的若干新进展与展望
[J].干旱是中国影响范围最广、造成经济损失最严重的自然灾害之一,直接威胁国家粮食安全和社会经济发展,对干旱问题的认识和研究有助于提升国家防旱减灾能力。自新中国成立以来,中国对于干旱气象的研究取得了丰硕的成果。本文以21世纪以来中国气象局干旱气候变化与减灾重点开放实验室为平台开展的与干旱气象相关的科研项目群取得的研究成果为基础,通过成果检索,对干旱监测技术、干旱时空分布规律、干旱致灾特征、干旱灾害风险及其对气候变暖的响应以及干旱灾害风险管理与防御技术等方面的新进展进行总结和归纳。同时,基于干旱气象研究的前沿发展趋势,提出中国未来干旱气象研究应在加强气候变化背景下干旱高发区综合性干旱观测试验基础上,从不同维度和尺度定量研究干旱形成机理,构建多源数据融合和多方法结合的综合干旱监测新方法,揭示干旱致灾机理,科学评估干旱灾害风险,提出具有可执行性的风险管理策略等重点科学问题上取得突破。这对于推动中国干旱气象研究具有积极意义。
基于随机森林模型的干旱预测研究
[J].随着全球气候变化,人类活动干涉,干旱发生的频率逐年增加,影响范围也不断扩大。对干旱进行有效的预测以提前采取应对措施减少极端天气对社会的影响是极为必要的。由于影响干旱发生的如气候、水文等因素十分复杂,应采用合适的方法预报具有非线性特征的干旱.本文以气象干旱评判标准SPI划分干旱为三等级,并以前期12个月的降雨与从74项大气环流因子中初步筛选出30项因子共372个因子作为初步筛选集,通过Incnodepurity指数挑选出重要性排在前30的因子作为模型解释变量,采用RF模型对淮河流域21个代表站的1962-2012年各月干旱等级进行分析。以1962-2006年作为模型检验期,2007-2012年作为模型预测期,整体预测平均准确率为73.0%,高于气候系统的天气预报准确率,可在不同区域进行推广应用。
中亚复合高温干旱事件识别与特征分析
[J].由于复合高温干旱事件造成的综合效应远超普通干旱事件,复合高温干旱日益受到人们关注。基于中亚地区1981—2020年欧洲中期天气预报中心的第五代再分析陆地产品(Land Component of the Fifth Generation of European Reanalysis,ERA5-Land)的逐小时温度数据、月尺度潜在蒸散量数据和日尺度多源集成降水产品,计算标准化降水蒸散指数(Standardized Precipitation Evapotranspiration Index,SPEI)和日最高温度,识别复合高温干旱事件并分析其特征,得到以下结论:(1)复合高温干旱事件在中亚各地区空间分布上呈非集中趋势,1980年代、1990年代、2000年代和2010年代发生频次较高的区域分别位于东南部、北部、西北部和西部;(2)这些事件的时间分布表现出由大波动变为平稳小波动的趋势,且2020年之后将维持此平稳状态;(3)分析1984、1993、2010、2020年4个复合高温干旱事件典型年份,发现1984年高温干旱主要集中在中亚东南部,1993年仅零星地区偶发,2010年北部多发复合高温干旱事件,2020年则集中于西部地区。
Inter-decadal variations, causes and future projection of the Asian summer monsoon
[J].
An introduction to variable and feature selection
[J].
The interannual relationship between anomalous precipitation over Southern China and the south eastern tropical Indian Ocean sea surface temperature anomalies during boreal summer
[J].
Classification and regression trees
[J].
Oceanic forcings of the interdecadal variability in East Asian summer rainfall
[J].


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}